All NVIDIA GPUs starting with the Kepler generation support fully-accelerated hardware video encoding, and all GPUs starting with Fermi generation support fully-accelerated hardware video decoding. As of July 2019 Kepler, Maxwell, Pascal, Volta and Turing generation GPUs support hardware encoding, and Fermi, Kepler, Maxwell, Pascal, Volta and Turing generation GPUs support hardware decoding.
The processing demands from high quality video applications have pushed limits for broadcast and telecommunication networks. Consumer behavior has evolved, evident in the trends of OTT video subscription and the rapid uptake of live streaming. All social media applications now include the feature on their respective platforms. Live streaming will drive overall video data traffic growth for both cellular and Wi-Fi as consumers move beyond watching on-demand video to viewing live streams.
Video content distributed to viewers is often transcoded into several adaptive bit rate (ABR) profiles for delivery. Content in production may arrive in one of the large numbers of codec formats that needs to be transcoded into another for distribution or archiving.
This makes video transcoding a critical piece of an efficient video pipeline – whether it is 1:N or M:N profiles. The ideal solution for transcoding needs to be cost effective in terms of cost (Dollar/stream) and power efficiency (Watts/stream) along with delivering high quality content with maximum throughput for the datacenter. Video providers want to reduce the cost of delivering more content with great quality to more screens.
The massive video content generated on all fronts requires robust hardware acceleration of video encoding, decoding, and transcoding. Let’s take a look at how NVIDIA GPUs incorporate dedicated video processing hardware and how you can take advantage of it.
NVIDIA Encoding and Decoding Hardware
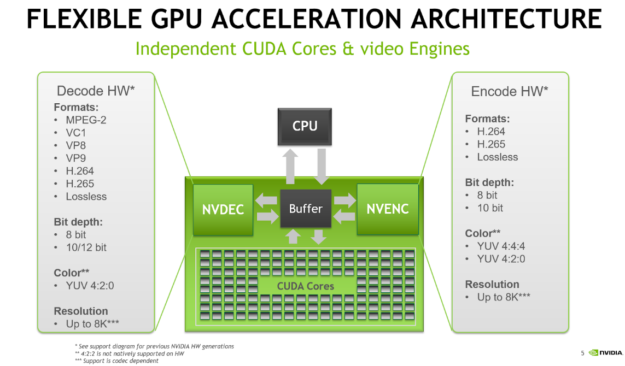
NVIDIA GPUs ship with an on-chip hardware encoder and decoder unit often referred to as NVENC and NVDEC. Separate from the CUDA cores, NVENC/NVDEC run encoding or decoding workloads without slowing the execution of graphics or CUDA workloads running at the same time.
NVENC and NVDEC support the many important codecs for encoding and decoding. Figure 1 lists many of the codecs, format and features supported with current NVIDIA hardware. Actual support depends on the GPU that is used. An up-to-date support matrix can be found at the Video Encode and Decode Support Matrix page.
Figure 1: GPU hardware capabilities
Hardware accelerated transcoding with FFmpeg
Using the FFmpeg library is common practice when transcoding video data. Hardware acceleration dramatically improves the performance of the workflow. Figure 2 shows the different elements of the transcoding process with FFmpeg.
Figure 2: Transcoding pipeline with FFmpeg using NVIDIA hardware acceleration
FFmpeg supports hardware accelerated decoding and encoding via the hwaccel cuda, h264_cuvid, hevc_cuvid and h264_nvenc, hevc_nvenc modules. Activating support for hardware acceleration when building from source requires some extra steps:
selects the software H.264 encoder for the output stream
-b:v 5M
sets the output bitrate to 5Mb/s
But this is going to be slow slow since it only uses the CPU-based software encoder and decoder. Using the hardware encoder NVENC and decoder NVDEC requires adding some more parameters to tell ffmpeg which encoder and decoders to use. Maximizing the transcoding speed also means making sure that the decoded image is kept in GPU memory so the encoder can efficiently access it.
ffmpeg -hwaccel cuda -hwaccel_output_format cuda -i input.mp4 -c:v h264_nvenc -b:v 5M output.mp4
-hwaccel cuda
chooses appropriate hw accelerator
-hwaccel_output_format cuda
keeps the decoded frames in GPU memory
-c:v h264_nvenc
selects the NVIDIA hardware accelerated H.264 encoder
Without the -hwaccel cuda -hwaccel_output_format cuda option, the decoded raw frames would be copied back to system memory via the PCIe bus, shown in figure 3. Later, the same image would be copied back to GPU memory via PCIe to encode on the GPU. These two additional transfers create latency due to the transfer time and will increase PCIe bandwidth occupancy.
Figure 3: Memory flow without hwaccel
Adding the -hwaccel cuvid option means the raw decoded frames will not be copied and the transcoding will be faster and use less system resources, as shown in figure 4.
Figure 4: Memory flow with hwaccel
Given PCIe bandwidth limits, copying uncompressed image data would quickly saturate the PCIe bus. Prevent unnecessary copies between system and GPU memory, using -hwaccel cuda -hwaccel_output_format cuda result in up to 2x the throughput compared to the unoptimized call not using -hwaccel cuvid.
Processing filters
Transcoding often involves not only changing format or bitrate of the input stream, but also resizing it. Two options exist for resizing on the GPU: using the npp_scale filter or the nvcuvid resize option. The nvcuvid resize option can be used when transcoding from one input to one output stream with different resolution (1:1 transcode). See the next line for an example.
If multiple output resolutions are needed (1:N transcode), the scale_npp filter can resize decoded frames on the GPU. This way we can generate multiple output streams with multiple different resolutions but only using one resize step for all streams. See the next line for an example of 1:2 transcode.
Using -vf "scale_npp=1280:720" will set scale_npp as filter for the decoded images
The interpolation algorithm can be defined for scale_npp as an additional argument. Cubic interpolation is used by default but other algorithms might give better results depending on scale factor and images. Using the super-sampling algorithm is recommended for best quality when downscaling. See below for an example:
ffmpeg -vsync 0-hwaccel cuda -hwaccel_output_format cuda -i input.mp4 -c:a copy –vf scale_npp=1280:720:interp_algo=super-c:v h264_nvenc -b:v 5M output_720.mp4
Mixing CPU and GPU processing
Sometimes it might be necessary to mix CPU and GPU processing. For example you may need to decode on the CPU, because the format is unsupported on the GPU decoder, or because a filter is not available on the GPU. In those cases, you can’t use the -hwaccel cuvid or -hwaccel cuda flag. Instead, you need to manage uploading the data from system to GPU memory using the hwupload_cuda filter. In the example below, an H.264 stream is decoded on the GPU and downloaded to system memory since -hwaccel cuvid is not set. The fade filter is applied in system memory and the processed image uploaded to GPU memory using the hwupload_cuda filter. Finally, the image is scaled using scale_npp and encoded on the GPU.
Encoding and decoding work must be explicitly assigned to a GPU when using multiple GPUs in one system. GPUs are identified by their index number; by default all work is performed on the GPU with index 0. Use the following command to obtain a list of all NVIDIA GPUs in the system and their corresponding ID numbers:
ffmpeg -vsync 0-i input.mp4 -c:v h264_nvenc -gpu list -f null–
Once you know the index, the -hwaccel_device index flag can be used to set the active GPU for decoding and encoding. In the example below the work will be executed on the gpu with index 1.
ffmpeg -vsync 0-hwaccel cuvid -hwaccel_device 1-hwaccel cuda -hwaccel_output_format cuda -i input.mp4 -c:a copy -c:v h264_nvenc -b:v 5M output.mp4
Optimizations
All encoder and decoder units should be utilized as much as possible for best throughput. nvidia-smi can be used to generate real-time information about NVENC, NVDEC and general GPU utilization.
nvidia-smi dmon
nvidia-smi -q -d UTILIZATION
Multiple actions may be taken depending on those results. If encoder utilization is low, it might be feasible to introduce another transcoding pipeline that uses CPU decode and NVENC encode to generate additional workload for the hardware encoder.
PCIe bandwidth might become the bottleneck when using CPU filters. If possible, filters should run on the GPU. Several CUDA filters exist in FFmpeg that can be used as templates to implement your own high-performance CUDA filter.
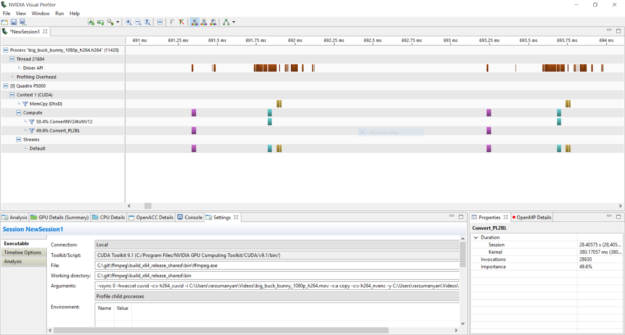
You can always track GPU utilization and memory transfers between host and device by profiling the ffmpeg application using the Nvidia Visual Profiler, part of the CUDA SDK. Simply launch “Run application to generate CPU and GPU timeline” and select the ffmpeg application with relevant CLI options. The application timeline is illustrated on fig. 5
Figure 5: ffmpeg application timeline
Turquoise blocks show colorspace conversion done by CUDA kernels while yellow blocks show memory transfer between host and device. Using Visual profiler allows users to easily track operations done on GPU, such as CUDA-accelerated filters and data transfers to ensure no excessive memory copies are done.
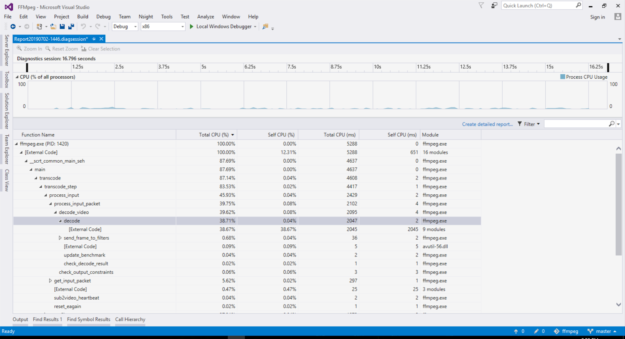
Collect CPU-side perforamnce statistics by compiling ffmpeg with the --disable-stripping CLI option to enable performance profiling.
This prevents the compiler from stripping function names so that commodity profilers like Gprof or Visual Studio profiler can collect performance statistics. CPU load level should be low with hardware acceleration on and most time should be spent within the Video Code SDK API calls, which are marked as “External Code” as function names are stripped from driver libraries. Figure 6 shows an example screenshot.
Figure 6: ffmpeg performance profiling with Visual Studio
FFmpeg is a powerful and flexible open source video processing library with hardware accelerated decoding and encoding backends. It allows rapid video processing with full NVIDIA GPU hardware support in minutes. Commodity developer tools such as Gprof, Visual Profiler, and Microsoft Visual Studio may be used for fine performance analysis and tuning. Check out the ffmpeg sources and give it a go!