
根据卡饭root1605发表的Hello Linux系列整理,本文获其许可转发,向root1605表示感谢
原文:
https://bbs.kafan.cn/thread-2107544-1-1.html
https://bbs.kafan.cn/thread-2109639-1-1.html
https://bbs.kafan.cn/thread-2112580-1-1.html
https://bbs.kafan.cn/thread-2113713-1-1.html
https://bbs.kafan.cn/thread-2115881-1-1.html
Hello , Linux(一):初入Linux的世界
目录
Ⅰ 前言&提醒
Ⅱ Linux的传奇之路
Ⅲ Linux的桌面环境
Ⅳ 什么是Shell
Ⅴ对Linux认识的一些常见误区
Linux是什么?在电影中的“黑底白字”的命令行?“黑客”的专用系统?在很多人看来,有很多“大神”用Linux作为操作系统,所以也“向往”Linux,但“有大神用Linux不代表用Linux的都是大神”,如果真正学到一些知识,无论Windows还是Linux,都可以当“大神”(当然,指的是了解一些基础知识,熟练的使用,加懂些操作系统的简单原理)。如果想要接触一项新事物,就要谦虚的学习,使用Linux而反过来鄙视其他操作系统没有任何意义,在Linux上听音乐和在Windows上听音乐并不存在高下。你可以在Linux上学到很多东西,但是同时,Windows上也可以学到很多东西。
本系列文章主要涉及Linux的基础知识,主要面向对象是对Linux感兴趣的系统爱好者,。折腾没有错,但正确的理论必不可少,否则你可能是反复卸载安装系统,从一个发行版到另一个发行版,从一个桌面环境到另一个桌面环境,费力地配置Wine环境,结果最后连“挂载点”这样的基础概念也不知道。
这些文章并不局限于某一Linux发行版本,不会涉及架设网站服务器,配置群集等等,更不会涉及所谓黑客技术,主要是面向个人桌面端相关的只是。并没有哪一本书可以让你从入门到精通,这些文章同样没有神奇的本领,但你可以因此对Linux有基本的了解,并能够在日常场景中熟练使用它。
友情提示,对于Linux的文件系统,启动引导等内容会在以后讲述,如果现在就想安装Linux操作系统,建议使用虚拟机或者一台空闲的计算机,Linux安装本不危险,但可怕的是所谓“实践中学习”,尤其你在Windows就有随便执行网上流传的命令行而不管懂不懂,或者任意修改关键配置文件的习惯。随意操作,你的数据很可能会丢失(而且不像Windows上那么容易通过软件恢复),也可能经常导致系统无法引导,一遍又一遍重装,最终丧失学习的热情。各个常用的发行都可以使用,比如Deepin,Ubuntu,Linux Mint,Cent OS等等(排名没有顺序)。
楼主不是Linux爱好者,也不是所谓“软粉”,如果有任何问题,会尽可能地改正。有问题我会尽力回答,但关于“Linux和Windows哪个好”,“怎样配置Windows和Ubuntu双系统”,“哪里有破解版的CrossOver”,“怎样在Linux下运行英雄联盟”之类的问题一概不予解答,还请谅解。
![]()
![]()

![]()
不要害怕“Shell”这个词语,把它和“黑客”“入侵”之类的内容联系在一起。在很久以前,在图形化界面还没有占领计算机的时候,需要输入文本格式的命令与计算机交互。在UNIX中,有一种解释命令的程序,被称做Shell,在Linux中也是。
如果简单的把系统分为内核(Kernel)和外壳(Shell),那么外壳是负责接收用户的指令并传递给内核的处理的,如果需要处理后的数据传出,也得经过外壳。有时候我们所说的Shell也可以指图形化的用户界面,毕竟它也算是外壳(这句话不是十分严谨,此处仅作理解只用),但更多的时候谈到Shell,不包括图形化的界面。
Shell接受来自用户的指令,经过解析后,传递给系统执行,之后系统在反馈给用户信息,这就是Shell。不光是Linux上有Shell,Windows上也有,比如Windows PowerShell。Linux各个发行版一般都包含了很多种类的Shell,比如C Shell,Korn Shell,Bash Shell等,因为它们功能类似(不是所有的Shell都功能类似,这里指的是常用的),所以只介绍Bash Shell一种,使用方法其实都大同小异,熟悉一种的话,稍加学习即可切换到另一种。
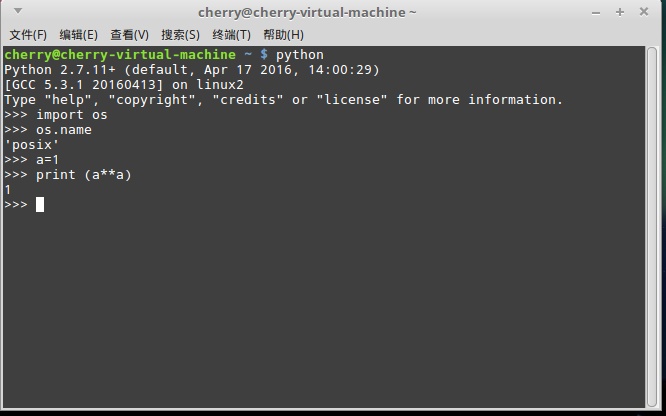
在你的Linux发行版上,打开“终端”(不同的发行版可能名称不一样),就会出现一个文本命令窗口,这个窗口一般默认接受Bash Shell的命令。如需要切换到自己喜欢的Shell,比如Python,输入python即可,如果没有安装相关的Shell,可以自行下载安装,由于怎样安装软件这篇文章不会介绍,所以请自行搜索方法,或者先使用Bash Shell。

可能你觉得使用Shell是多此一举,因为已经有桌面环境了,还对着这个黑窗口干什么?当然,你只是拿Linux听音乐,看电影,一般就不需要Shell了,可当进行系统管理的时候,如果该发行版没有提供某项设置的图形界面,就需要Shell,一些功能在图形界面很难或无法实现,比如,筛选出/home文件夹中所有名称满足“数字+一个英文单词+日期”且修改日期在2017年9月1日之后的文件并列表,这对于仅使用图形化桌面几乎是不可想象的任务,一般只能通过人工筛选,或者借助第三方软件(如果有的话)。Shell中可以使用编程语言中的各种结构,比如选择,循环等等,还可以调用一些第三方的库,十分方便而简洁。借助Shell,可以很轻松完成一些自动化的工作等。
其实“命令行恐惧症”是没必要的,它不是混乱邪恶的C++(开个玩笑),用法很简单,不要担心背命令,楼主认为这没有必要,常用的命令,用的多了自然会记下来,不常用的,用的时候再查就行了,反正帮助系统十分发达,至少不需要你去查图书馆某项命令怎么用。
虽然在终端中输入命令,输一条执行一条,下一次再打开终端就没有以前的命令了,但是假如一些命令需要重复执行,不想每次都输一遍,怎么办呢?其实把命令保存成文本文件,每次运行这个文本文件就可以了,这个文件称为脚本。下图是一个Perl语言写的脚本,用来安装VM Tools。
如果你此时有Linux发行版,可以尝试着执行以下的命令(不会修改系统配置,仅是演示),现在不需要看懂它,最后一个是Python脚本。
- #/bin/bash
- i=0
- for name in *.*
- do
- b=$(ls -l $name | awk ‘{print $5}’)
- if test $b -ge $a
- then i=$b
- namemax=$name
- fi
- done
- echo “the max file is $namemax”
复制代码
- #/bin/bash
- echo “No Password User are :”
- echo $(cat /etc/shadow | grep “!!” | awk ‘BEGIN { FS=”:” }{print $1}’)
复制代码
- #!/bin/bash
- echo “please enter three number:”
- read -p “the first number is :” n1
- read -p “the second number is:” n2
- read -p “the third number is:” n3
- let MAX=$n1
- if [ $n2 -ge $n1 ]; then
- MAX=$n2
- fi
- if [ $n3 -ge $MAX ]; then
- MAX=$n3
- fi
- echo “the max number is $MAX.”
复制代码
- #!bin/bash
- read –p “please input a username:” USER
- if cut –d:-f1 /etc/passwd | grep “^$USER[ DISCUZ_CODE_3 ]quot; &> /dev/null ;then
- MYBASH=`grep “^$USER:” /etc/passwd | cut –d : -f7`
- echo “${USER}’s shell is $MYBASH”
- else
- echo “$USER not exists.”
- exit 4
- fi
复制代码
- #!/usr/bin/python
- import re
- line = “Cats are smarter than dogs”;
- matchObj = re.match( r’dogs’, line, re.M|re.I)
- if matchObj:
- print “match –> matchObj.group() : “, matchObj.group()
- else:
- print “No match!!”
- matchObj = re.search( r’dogs’, line, re.M|re.I)
- if matchObj:
- print “search –> matchObj.group() : “, matchObj.group()
- else:
- print “No match!!”
复制代码
![]()
对Linux认识的常见误区
1.Linux是用来编程的,Windows不适合拿来编程
首先要看你是怎样”编程“,举个例子,你要学习C++语言,是一个从”cout<<”hello world”<<endl;”开始的人,这两个平台并没有什么大的差异,想学习命令行编译,这两个平台都有,想使用IDE的话,Windows上有强大的IDE Visual Studio,只是你可能暂时没有能力接触很多的高级功能。有人说Windows屏蔽了”代码是如何生成的,makefile怎么写“,其实只是Visual Studio给你封装好了加快你的工程进度而已,想看的话也完全可以看到。在Linux下如果使用IDE,也可能不会直接”看到”。
如果你是某一领域里的编程人员,选择哪个平台,往往是工作性质所决定的,比如,从事Windows内核驱动开发相关职业,去用Linux是自找麻烦,如果是专门编写Linux桌面应用的人员,也许选择Linux会方便一点,至于有些人说的“Windows 配置开发环境没有Linux下方便”之类的问题,有些情况下也存在,有些东西不是Windows上不能做,而是太麻烦,Linux亦然,Linux和Windows都作为工具,都应该为人所利用,如果Linux能够提高你的效率,那么你就适合Linux,如果你的工作在Windows 下完成更为简便,那么就选择Windows,本来很简单的道理,让Windows似乎成了编程的禁地,那么,数量那么庞大的Windows应用程序是怎么出来的?
如果你想学习操作系统原理之类的课程,那么Linux可能更适合你去研究,不过,在学习之前,必须要有相关专业知识的储备,并不是你有Linux内核的代码,你就可以读懂,并成为熟悉操作系统内核的人,指望着光看源代码来学习操作系统,很难。Windows也有一些代码在传播,比如WRK(Windows Research Kernel),仅仅是学习操作系统原理的话,已经够了。当然,在有能力学习操作系统内核原理时,Linux是一个更好的平台。
2.关于Ubuntu Kylin
Ubuntu Kylin不是国产操作系统,开发人员也从没有说过这是国产操作系统,它只是一个普通的Linux发行版本(Ubuntu官方的一个中国定制版),但是融入了一点中国元素,考虑了下中国人的使用习惯而已。至于其他”麒麟“系统,这里不多说,请自行搜索相关信息。
3.Linux的安全性稳定性比Windows好
这个结论又很武断了。Linux内核的稳定性也许比Windows好,但不代表Linux的各个发行版都比Windows好,而且不同版本的Windows和Linux稳定性都不一样。稳定性有时候不光靠操作系统,也得看使用的人。 给普通用户感觉Linux比Windows安全的原因是很少听到Linux病毒的爆发,也很少有所谓流氓软件。有一个原因是桌面端用户Windows占了绝大部分份额,不是因为Linux的安全性。如果国内有一半的个人电脑用Linux,那么在Windows上出现的同样会上演。
由于这系列文章才刚刚开头,所以有些对Liunx的误解暂时无法在这里解答,会在以后讲述相关知识后再提。虽然本文的内容不多,但对于第一次接触Linux系统的人来说,已经有大量的信息需要去理解。本文到此结束。
Let’s Start !

目录
Ⅰ 前言
Ⅱ 一切都是文件
Ⅲ Linux命令初识
Ⅰ前言
抽象的思维方式
不管是对于专业人员,还是业余爱好者,操作系统的机理都不是那么简单的,很多情况下,如果没有相关知识的积淀,即使你接触到某个系统机制背后的原理,你也无法或很难理解。对于不同程度的学习,就需要有不同的思维方式。从底层向上学习是可以的,如果方法得当,你能建立起坚实的地基,并很容易的在上面进行拓展,但这样对于非专业人员,不一定都合适,或者说代价很大。在你第一次使用Windows前,应该还没有接触过“寄存器”“堆栈”这些概念,然而你已经“会用”Windows操作系统了。当然,抽象思维是有局限性的,有些时候抽象思维不能真正理解一些东西
换句话说,你可以忽略(暂时或永久)一些细节。这就像听收音机一样,作为普通使用者,你只需要懂得那几个按钮怎么用就行,作为维修人员,你就需要懂得其内部构造了,作为设计工程师,你可能需要相关的很多知识。
软件开发人员也会使用抽象思维来开发应用程序以及操作系统等,比如Java中的各种包,C++ 标准模板库中的“迭代器”等等。
为什么讲的不“深入”
讲的深入,学习者需要代价。并不存在所谓“入门到精通”的神话,要想学习Linux“深入”的地方,需要一个立体的知识网络,拿它来架设DNS服务器,你需要网络相关知识,拿它来学习操作系统原理,你需要的知识会更多。本系列文章不会特别涉及特定领域的应用,也不过分提到Linux编程,会有一些相对深入的内容,前几篇会注重广度,而后面的内容会详细的介绍一些需要详细理解的知识。但让楼主拿Linux作为平台,写什么“Intel 保护模式从入门到精通”之类的内容,肯定是不现实的。
![]()
Ⅱ 一切都是文件
不管你之前有没有被“挂载点”“根目录”“VFS机制”等一大堆混杂在一起的术语所困扰过,反正要使用Linux,这些知识都需要理解的。下面就对这些知识做一些介绍。
买个人电脑时,现在一般都预装的是Windows操作系统,少部分是Linux的某各发行版(比如Ubuntu),甚至还有没有操作系统的。要安装Windows操作系统时,我们都会碰到一个“分区”的概念,尤其是在一块全新的硬盘上安装操作系统,或者某些人“干掉”预装的正版Windows,切换到旧版本Windows时。我们下面就运用一下上文所提到的“抽象思维”。
硬盘,通俗的理解,就是永久性存储数据的设备,不同于断电就丢失数据的内存。把它当作一个书柜,是的,它可以装书(这算是废话),但我们的书柜好像都是分层的吧?每一层,放相应的书。一不小心把某一层的书弄乱了,也不至于影响其它层的书。想象一下把这些隔板全都抽掉,一旦某一本书没放好,你的书可能都会掉下来,它们是互相影响的。一块硬盘,也就可以抽象地认为是一个书柜。我们在Windows下熟悉的“分区”概念,就相当于“隔层”。如图是“C盘”。

先不考虑格式化C盘,分区具体有“哪些”作用,在大多数人眼中,C盘做系统盘,然后……大家都懂。就是数据从“逻辑上”隔离开,安装操作系统时,可以格式化系统盘,不影响其他盘(虽然,装系统不一定需要格式化分区)。这都没错。
如果我说,Linux下没有什么“C盘”,“D盘”,也许你会认为你的数据会很不安全。Linux下也可以“分区”,像Windows那样,只是,这些“分区”的组织方式不同。
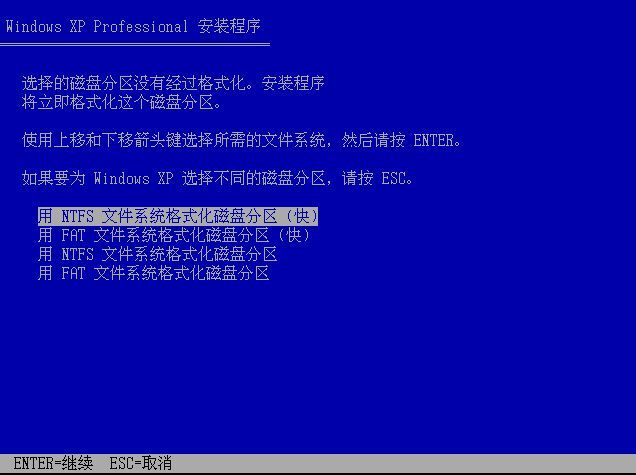
我们还原一下Windows下全新安装操作系统时“分区”的过程,首先有一块未分配的空间,创建一个个分区,设置大小,选择文件系统(一般为NTFS,再格式化,并将Windows操作系统安装在其中一个分区上(一般是C盘),如图。当然,安装后也可以调整分区的。
Linux在安装时,也大致是这样的,需要“分区”,实际上这里你可以认为分区之后,你已经有“几块”硬盘了。如图。创建“分区”时需要有文件系统格式,Windows上使用NTFS,一些特殊的分区(比如MSR分区,EFI分区等不是),而Linux使用(支持)的文件系统格式非常之多,有ext4,BtrFS,Reiser4,以及Windows所使用的NTFS(不能把Linux安装在那里)等,如果你的发行版不支持NTFS分区的读写,可以下载相关软件包。一般来说,如果你根本不清楚各个文件系统的适用条件,那么就选择ext4,一些具有特殊用途的分区除外。

创建“分区”总得能够使用它吧?下面就介绍Linux下的目录树结构。
Linux下的“磁盘”(也就是刚才分的区,把它们当作一个个磁盘来看待)不是“一等公民”,目录树,它就是一棵树,这个数的最顶端就是“/”目录(根目录),也就是说只有一个单独的顶级目录(目录类似于Windows中的文件夹)。而你的一个个“磁盘”需要“挂载”到某个目录,才能使用。比如你分了三个区,暂计为A,B,C。把B挂载到/home下,好了,这个时候访问/home目录,就相当于访问B盘,那么把A盘挂载到/目录(根目录下),根目录中的内容就存放到A中了,只是你访问文件的时候是直接访问/这个目录,而不是寻找一个A。那么问题来了,根目录是一且目录的根,根目录挂载到一个磁盘了,根目录下的某个目录挂载到另一个磁盘了,而这个目录又是“属于”根目录的,到底怎么回事?就举刚才这个例子,访问根目录目录下,你“感觉”不到你在访问磁盘,实际上你在访问A,根目录下属的/home目录,“打开”根目录还是会看到/home,但注意,这个时候只是在根目录中置放了一个/home目录的符号,一旦访问/home,就相当于跳转到了B,/home中的文件并不会占用A的空间。你不可能把根目录中的每一个目录都,比如/boot目录没有对应一个磁盘,那么它属于根目录,哪个磁盘挂载到了根目录,/boot目录中的内容就在这个磁盘中。所有目录都可以被挂载,你自己创建一个目录也可以。每个目录就是一个可用的“挂载点”。在Linux操作系统中,你可能更需要关心的是往哪个目录中存放文件,而不是哪个磁盘。
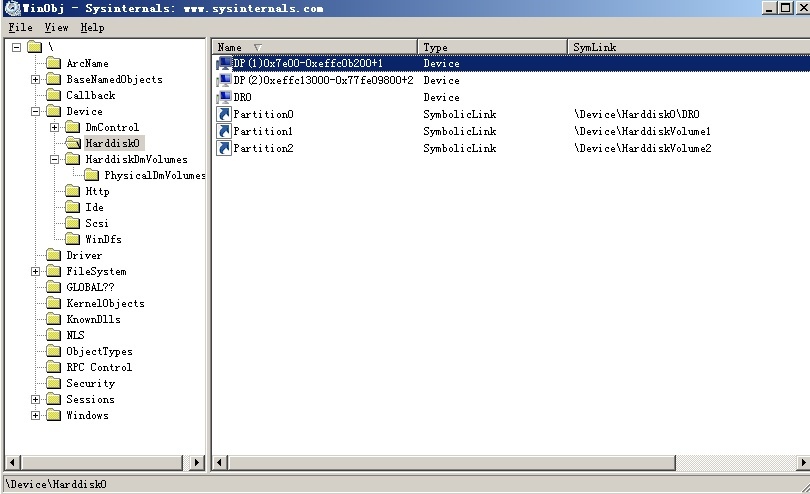
其实,Windows文件系统实际上也只有一个根,用户层面上看到的是C盘、D盘这些东西,不管怎么说,它们并没有所谓优劣之分,盲目黑微软是很幼稚的行为。在内核里,分区的组织结构如下图:
Linux下一切都是文件,是什么意思呢?我们不讨论它合不合理。“一切都是文件”需要VFS机制的支持。它向用户,应用程序,操作系统提供了一个通用的虚拟的接口,旨在一个操作系统中支持多个不同类型的文件系统。前面所说的的分区,就可以表示为/dev目录下的文件,比如/dev/hda(IDE设备),/dev/fd0(软盘)等等,/dev目录存放了设备文件,即设备驱动程序,假如使用了一张光盘,你需要将光盘内容挂载到一个目录,不是直接去访问/dev中的设备文件。/dev目录下甚至有一些不是设备的设备,比如/dev/null,它不代表什么真实的物理设备,类似于一个只写设备,向它写入的东西都会丢失掉,你也不会从它那里得到什么东西,类似于一个黑洞。
根目录下的文件夹,可以自行搜索各个的用途,这里不再赘述。在安装操作系统的时候,最好将/home目录挂载到一个分区,/home目录类似于你的个人文件夹,/必须挂载到一个分区,另外还需要一个交换空间(大约等于物理内存大小即可),如果是以UEFI模式启动,另需要一个EFI分区。不需要把分区挂载到/boot目录下面,除非你的计算机非常老,不支持大容量硬盘,如果是这种情况,请分区时让第一个分区挂载到/boot目录下。
![]()
Ⅲ Linux命令初识
上一篇文章中已经提到一些关于Shell的东西。不要去死记硬背命令和参数,用的多了自然记得住,用的少的命令,只要会查阅资料,很快就能使用,你不可能记住所有的命令。
这里所说的shell,也就是一个程序,接受从键盘输入的命令, 然后把命令给操作系统的相关模块去执行。所有的 Linux 发行版都提供一个名为Bash的来自GNU项目的shell。bash是最初Unix上由Steve Bourne写的sh的增强版,在Unix上,当时sh是不可或缺的。如果还不理解命令是什么,就看这个Windows下的命令提示符窗口,只是大多数人都认为它比Windows的命令提示符好用一些。Windows上有.bat脚本,就是把很多命令(以及相关的语法结构)组合在一起的批处理程序文件,Linux上的这种程序就叫做shell脚本。
如果使用图形用户界面时,需要另一个叫做终端仿真器的程序来输入命令。一般不同发行版中叫法不同,但你应该很容易找到它。
文本命令的shell只是一个工具,使用它,没有什么优越性可言,如果你的工作能够在这种方式下快速完成,那它就是好的方法,使用它不必去贬低图形界面。更不要受到一些影视作品的影响,误认为使用shell就是黑客,看着屏幕上刷刷的命令行以及输出认为自己就是高手了,那只是一种错觉,不行你在Ubuntu下试一下sudo apt-get update这个命令,也会出现一大堆的内容。
来做做实验:输入“pwd”,会发现屏幕上立即出现了当前的工作目录,比如/home/雨樱,然后你想列出当前目录下有什么东西,可以用“ls”命令,屏幕上会出现你要的东西,要想更改工作目录,像Windows上的命令提示符,用“cd /”即可(切换到根目录)。
“cd”命令带你去想去的地方,路径名可以由两种方式指定,一种是绝对路径,也就是从根目录开始,明确地写出你要去的目录的完整路径名,比如“/home/雨樱/pic/”,也可以用相对路径,也就是通过当前的目录进行“推导”,假设现在处于“/home/雨樱”目录,那么执行“cd ./pic”就可以了,“.”代表当前目录名。执行“cd ../music”表示,切换到上级目录下的“/music”目录,“..”表示上级目录。
一个命令可以是以下四种形式:
①一个可执行程序,比如输入“bc”,它实际上是一个计算器程序,显示到终端窗口中了。
②shell函数,之后介绍
③别名,之后介绍
④shell本身就提供的命令,比如“cd”命令。
输入“type”命令,屏幕上会显示出这是什么类型的命令。
下面举个例子,使用命令“tar”,语法是
- tar(选项)(参数)
- 选项
- -A或–catenate:新增文件到以存在的备份文件;
- -B:设置区块大小;
- -c或–create:建立新的备份文件;
- -C <目录>:这个选项用在解压缩,若要在特定目录解压缩,可以使用这个选项。
- -d:记录文件的差别;
- -x或–extract或–get:从备份文件中还原文件;
- -t或–list:列出备份文件的内容;
- -z或–gzip或–ungzip:通过gzip指令处理备份文件;
- -Z或–compress或–uncompress:通过compress指令处理备份文件;
- -f<备份文件>或–file=<备份文件>:指定备份文件;
- -v或–verbose:显示指令执行过程;
- -r:添加文件到已经压缩的文件;
- -u:添加改变了和现有的文件到已经存在的压缩文件;
- -j:支持bzip2解压文件;
- -v:显示操作过程;
- -l:文件系统边界设置;
- -k:保留原有文件不覆盖;
- -m:保留文件不被覆盖;
- -w:确认压缩文件的正确性;
- -p或–same-permissions:用原来的文件权限还原文件;
- -P或–absolute-names:文件名使用绝对名称,不移除文件名称前的“/”号;
- -N <日期格式> 或 –newer=<日期时间>:只将较指定日期更新的文件保存到备份文件里;
- –exclude=<范本样式>:排除符合范本样式的文件。
- 参数:
- 文件或目录:指定要打包的文件或目录列表。
复制代码
根据以上的信息,猜猜下面这些命令是什么意思?
tar -zxvf /opt/soft/test/log.tar.gz
tar -ztvf log.tar.gz
tar -jcvf log.tar.bz2 log2012.log
本篇文章不详细讲解语法相关知识,所以目前看不懂或者写不正确也没关系,专门的针对shell的文章在后面。
如果想知道一个命令的信息,怎么办?目前暂时提供三种方法:
①上搜索引擎,搜索相关用法,或者访问一些专门的网站,比如http://man.linuxde.net。这对新手来说相对友好。
②man命令,比如“man ls”,输入后,会有大量的关于“ls”这个命令的信息出现,比如参数,选项,示例等等。
③键入命令“whois ls”,即会接收到“ls”这个命令是干什么的的信息,
ls (1) – list directory contents
ls (1p) – list directory contents
④“info”命令例如“info ls”,
info页面比man page编写得要更好、更容易理解,也更友好,但man page使用起来确实要更容易得多。一个man page只有一页,而info页面几乎总是将它们的内容组织成多个区段(称为节点),每个区段也可能包含子区段(称为子节点)。理解这个命令的窍门就是不仅要学习如何在单独的Info页面中浏览导航,还要学习如何在节点和子节点之间切换。
更建议的是,有书作为参考,或者有人指导,刚开始时,你也许会不适应这种帮助文档,但很快,你会发现它很方便。
本篇文章的重点,在于理解Linux的目录结构,以及简单了解VFS机制,可能这些知识对于新手来说不那么友好,但熟悉之后会发现它也是很自然的设计。
目录
Ⅰ 前言
Ⅱ 体验命令行
Ⅲ shell输入输出
Ⅳ 硬链接与符号链接
学会使用shell≠精通Linux
打开黑乎乎的窗口,如泉水一般涌动的字符,是不是看起来十分的高端?所以可能会给某些同学带来一种学会使用shell就等于“精通Linux”一样,也许是受一些影视作品的影响吧!
“精通”本来就是一个很难界定的概念,什么是精通?是能够应付最普通的需求,还是能够在Linux平台上写一些小程序,或是熟悉Linux内核的实现原理,亦是其他的?然而,Shell也就是一个程序,它接受从键盘输入的命令, 然后把命令传递给操作系统去执行。几乎所有的 Linux 发行版都提供一个名为“bash”的来自GNU项目的shell,“bash” 是 “Bourne Again SHell” 的缩写(直译:目的地之上的壳,像是 电路板的外壳包装[如遥控器],这个包装拥有方便用户控制电路板指令的工具,可能是按钮,可能是滑杆,可能是触摸屏等等,而且形态各异;但无论形式如何都能让用户无需了解这块电路板的原理就能上手使用。bash便可粗略的认为是一种包装 —— 翼·风 注), 所指的是这样一个事实。
bash是最初Unix上的shell sh的加强版。本身没有什么特殊性,就像在Windows上使用图形界面一样,几乎所有人都懂得图形界面里那些按钮,文本框,选项卡是什么意思,GUI程序看上去也很友好,但一旦涉及到专业软件,比如Photoshop,Cakewalk Sonar,它们当然是GUI程序,但没有相关技能或知识并不能利用他们,可以认为GUI只是程序的一种表现形式,到底“高端不高端”取决于软件;再比如,有人用C语言写一些简单的算法程序,而Microsoft用它来写出Windows操作系统的大部分,都在使用C语言,但干的却不是一个“等级”的事情。
这些文章所提到的shell,不过是像教你认识在Windows下的按钮,选项卡是怎么一回事一样,是一些不怎么涉及其他专业知识的知识,你不能拿它来入侵某人的电脑,不够用来架设DNS服务器,当然,拿来在妹子面前炫耀下(楼主除外)还是绰绰有余的。
本文为什么有这么多例子?
楼主不认为给出一个很笼统的命令的用法就能让初次接触的人学会使用,这里不是简单的罗列命令,例子是必不可少的,但更多的命令需要自己依照一定的方法去“挖掘”。这篇文章和后几篇文章都会提到使用shell以及获取帮助的方法。
如果你安装了一个常见的Linux桌面发行版本,应该会自带一个叫“终端(Terminal)”或者“控制台(Console)”之类名称的应用程序,打开它们就可以启动shell。之前已经初步介绍过shell是什么,如果还不清楚,将它简单的看成Windows上面的cmd就行了,而这篇文章就是讲述怎样使用命令的。
打开终端后,输入第一个命令:
- pwd
复制代码
屏幕上会出现类似于下图(图1)的输出。

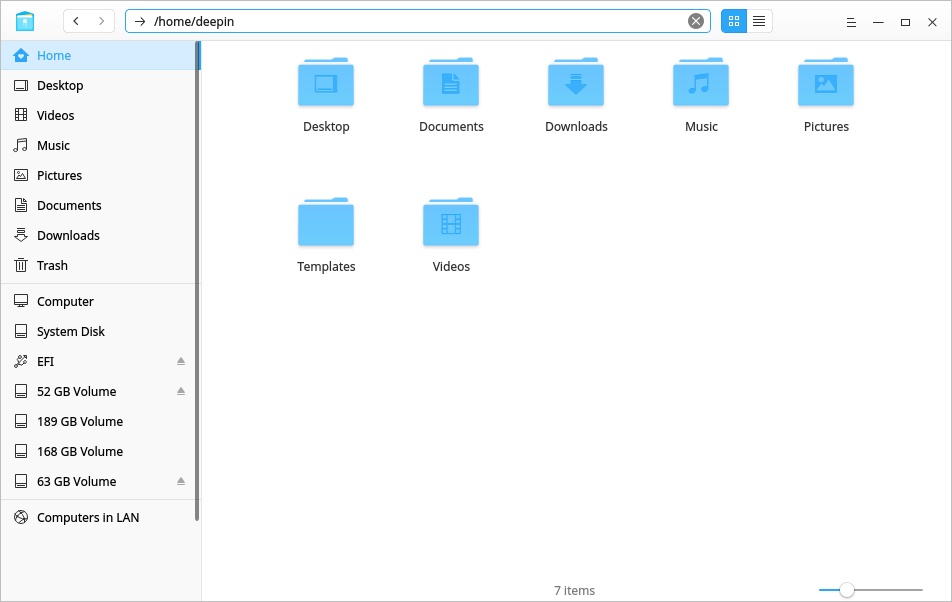
这个命令的作用很简单,是显示当前工作目录。什么是当前工作目录呢?我们都是用过图形界面的文件管理器,如图是Deepin的文件管理器,此时正处于/home/deepin中,你可以很清晰的看到当前目录,并通过双击进去下一个目录或者打开当前目录的文件。在shell中当前工作目录的含义是一样的。
这时候,通过双击文件管理器中的Videos文件夹,发现里面有一个文档,如图。
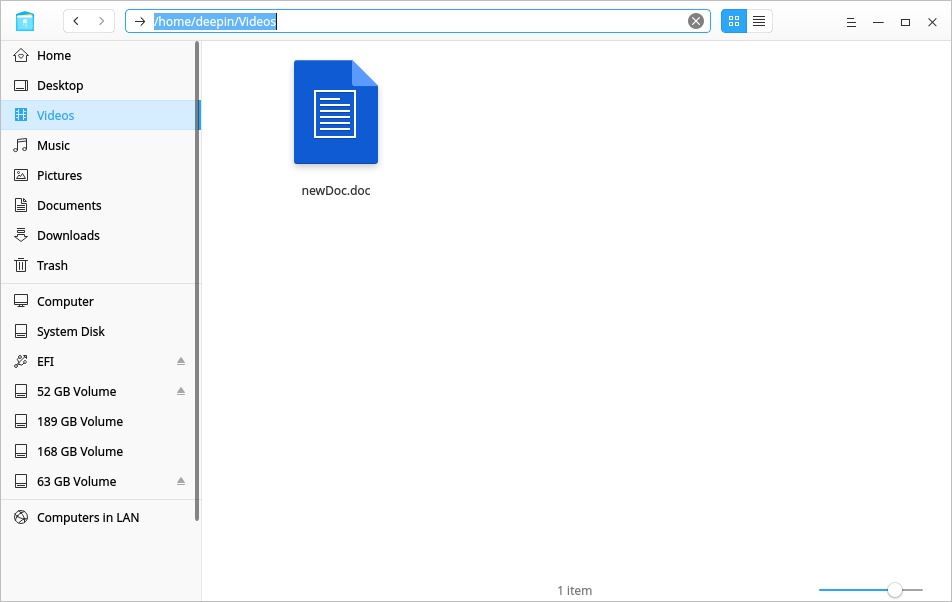
那么在shell中怎么进入到这个目录呢?输入命令(注意中间的空格,下同)
- cd /home/deepin/Videos
复制代码
这里使用了绝对路径。当然在已经打开的目录下,也可以用相对路径:
- cd ./Videos
复制代码
关于相对路径和绝对路径的知识请查看上一篇文章。输入命令如图(上一篇文章已经介绍这个命令,显示出命令的类型)
- type cd
复制代码
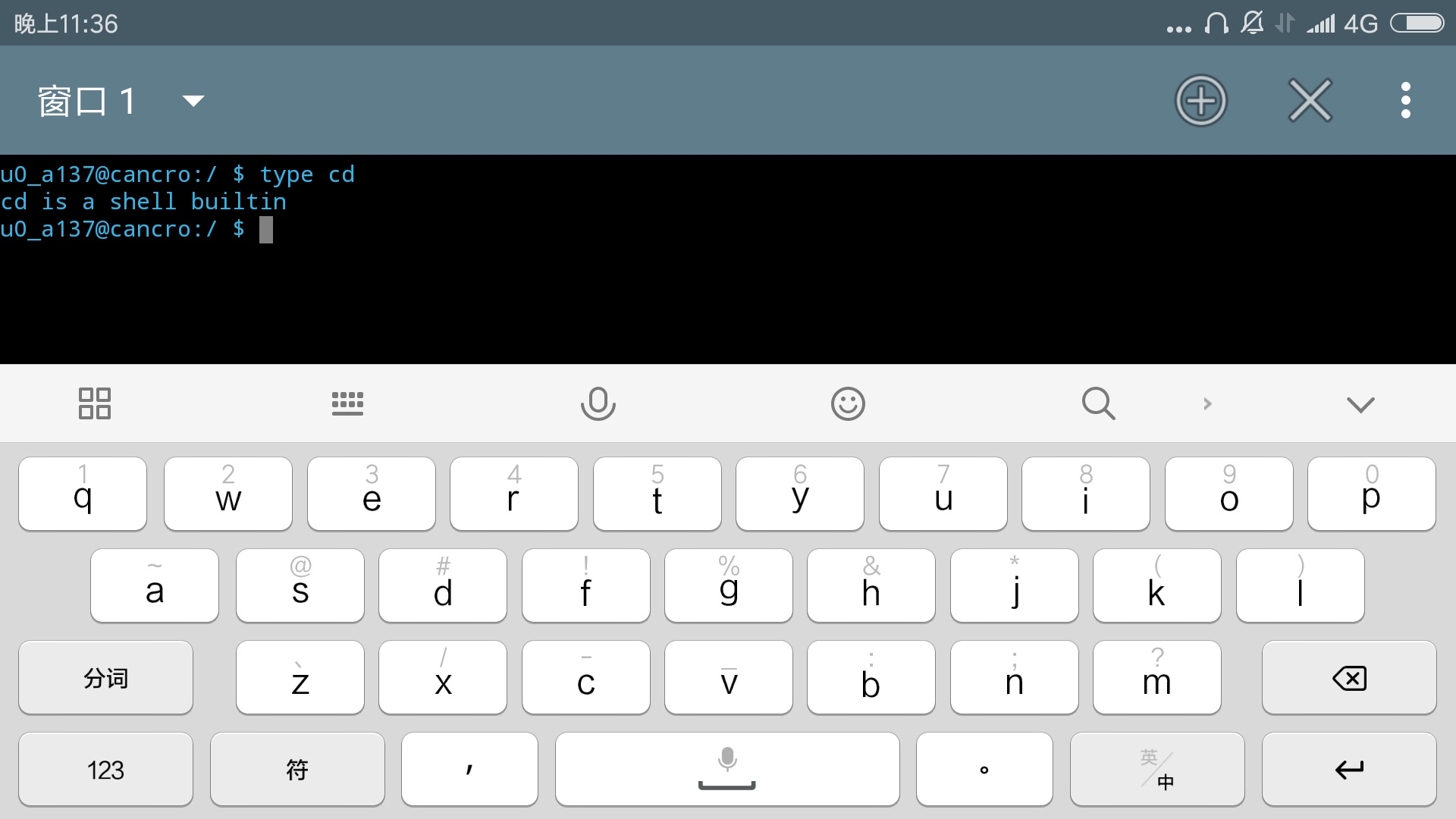
可以看出是一个shell内置的命令。还记得上篇文章所说的其他几种类型的命令吗?比如,是一个可以执行的程序,请输入
- type dd
复制代码
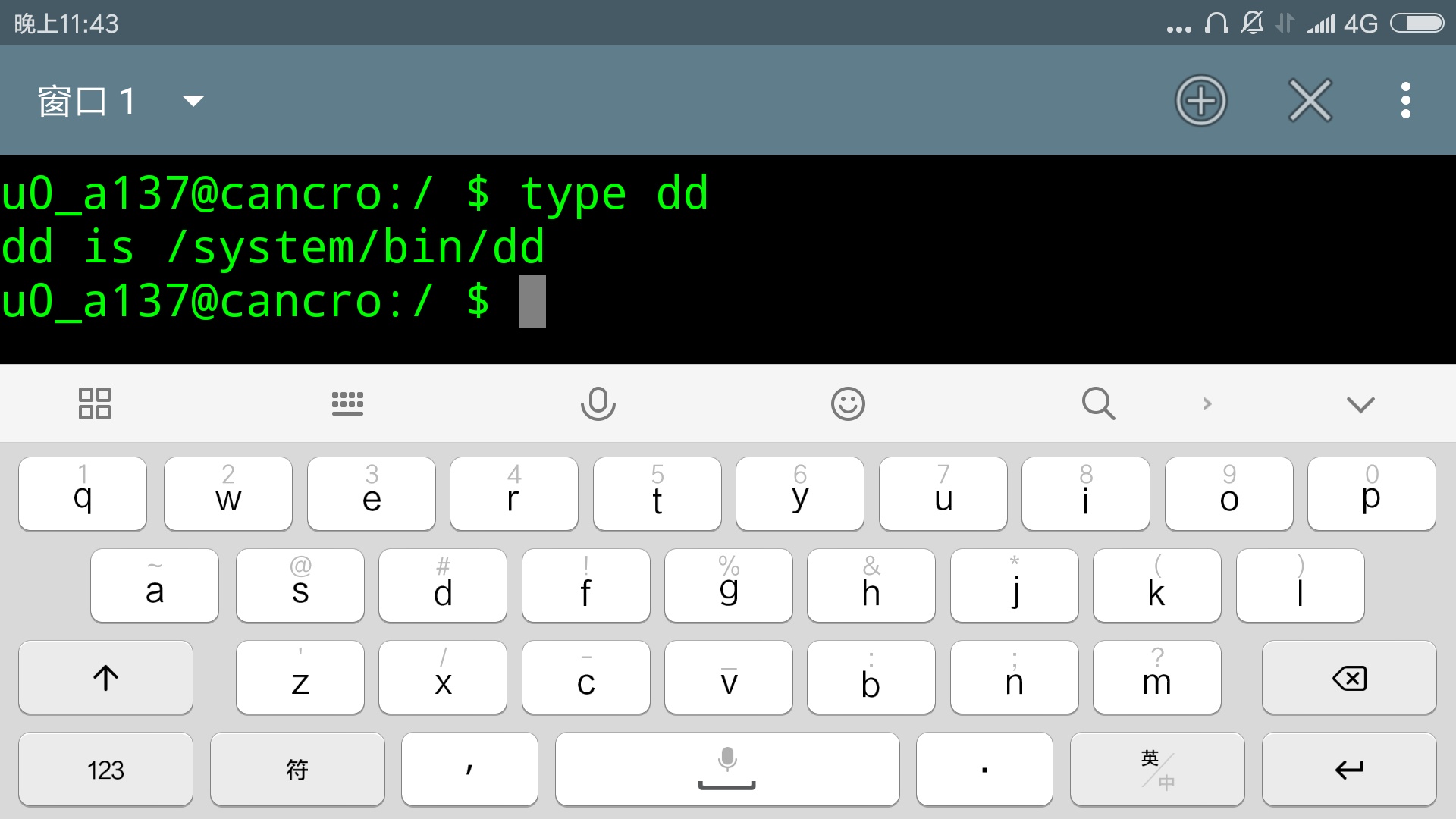
由输出结果可知,dd是system某个子目录下的可执行程序。
它是一个可执行程序,dd这个命令这里不介绍,以后可以自己探究。
可能你也已经意识到了,在输入“cd ./Videos”的时候,cd后面的“.Videos”指的就是要切换到的目录,“cd”是命令本身。cd后面跟的是“参数”,要让“cd”成功,需要提供一个有效的地址,参数就代表了这个命令作用的对象,就像英文句子“She cried.”(主谓格式),She指的就是命令本身(主语),而cry指的是她干什么(谓语)。后面的一个命令“type dd”,也是如此,光指定了命令type还不行,它不知道自己应该提供给用户哪个命令的类型。当然,有的时候是没有参数的或者可以省略不写,比如“pwd”,因为不给它参数,它也知道提供给用户什么信息,有些命令可以省略参数,原因是它可以有自己的默认行为。参数该输入什么样的内容,表示什么含义,可以有几个参数等问题,是提前预订好的,你不可能在cd命令中加入参数www.baidu.com,或者后面跟着几十个目录,每个命令的参数都不一样,具体用法需要查询资料。
(翼·风 注:可以认为是这样的格式(注意空格作间隔):
命令 参数 选项
命令:命令的名称;
参数:该命令对应的参数。数量不定,若有默认值可省略。
选项:该命令对应的选项。数量不定,若有默认值可省略。
注意:均以空格为间隔。除了 命令 必须在首位,其余 参数、选项 顺序一般无严格要求。)
言归正传,我们已经在shell下切换到了/home/deepin/Videos中,如图
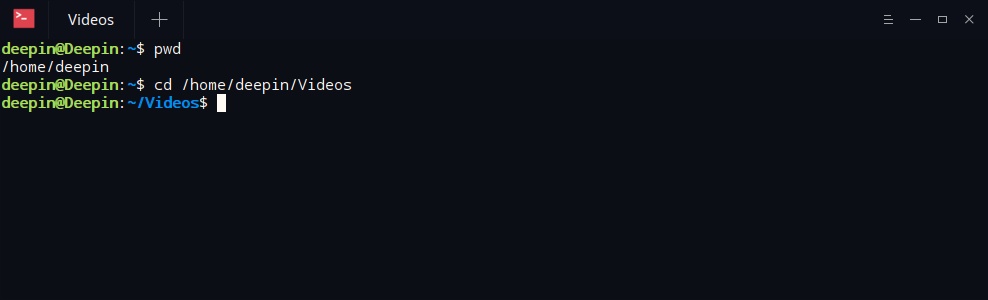
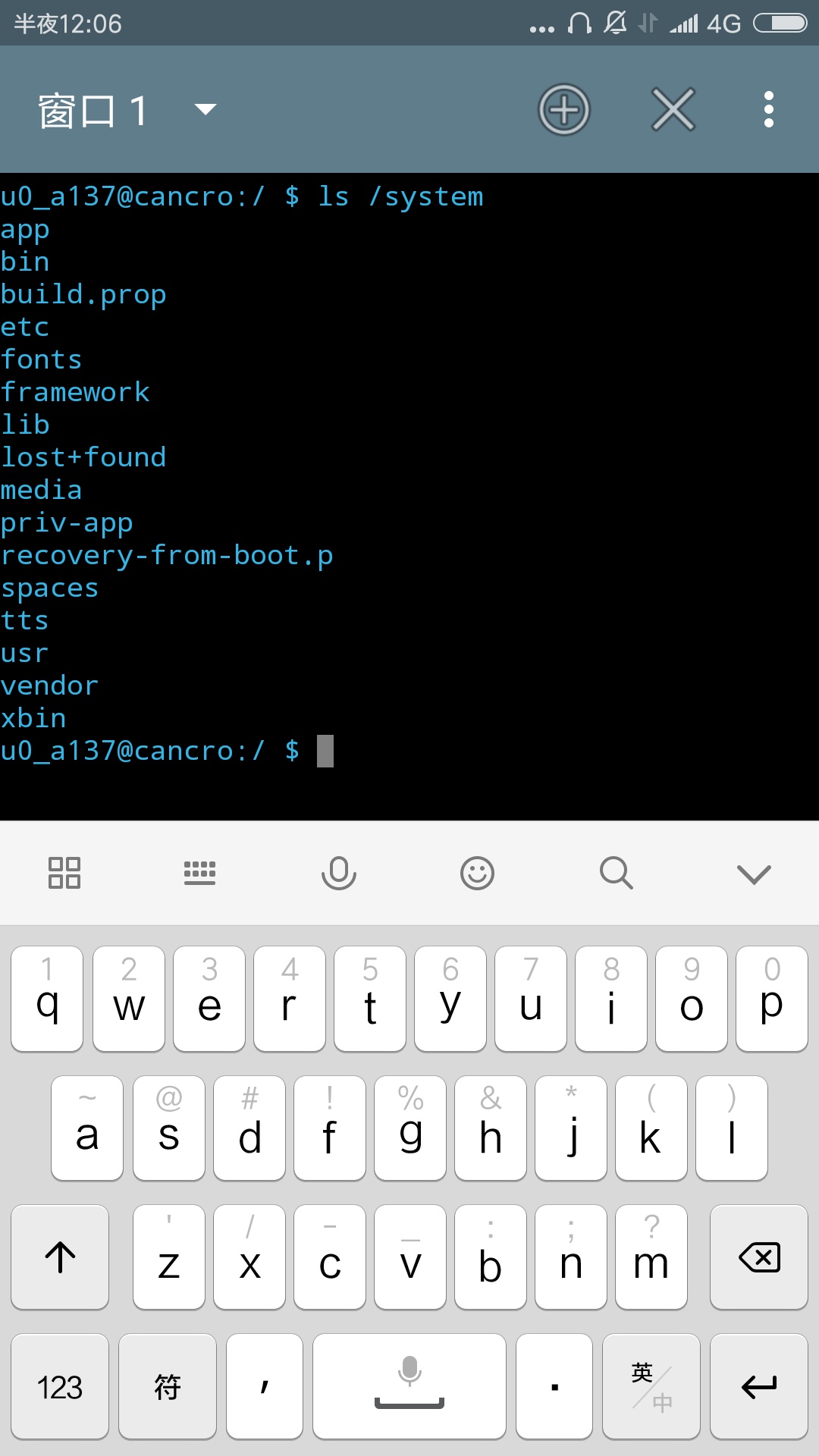
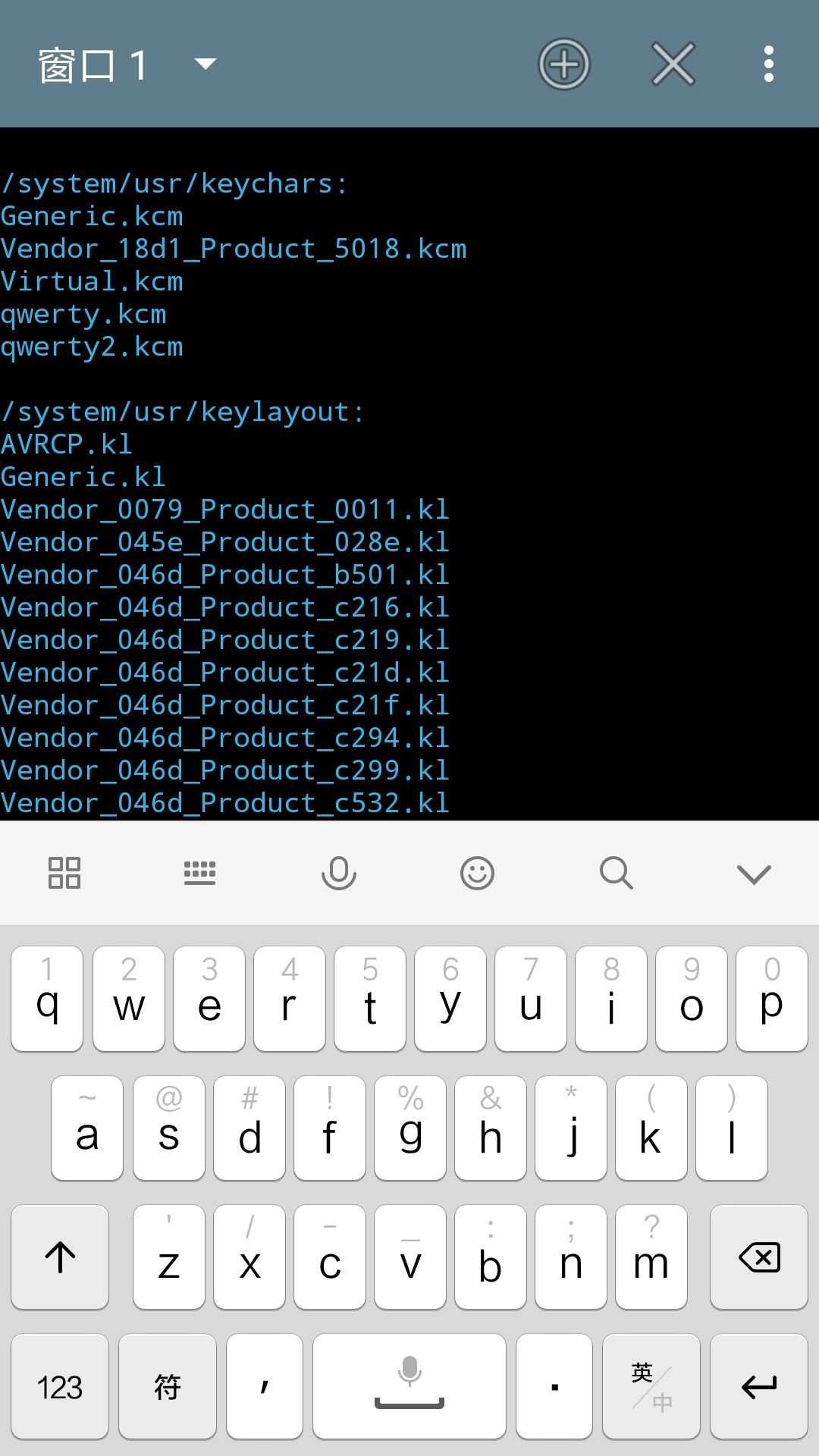
很显然我们还不知道这个目录下有什么东西,而在图形界面的文件管理器中可以很清晰看见当前目录下的文件。此时输入命令“ls”,即会列出来当前目录内的内容。ls命令参数可以没有,没有参数时,会默认列出当前目录内的内容,如果在后面跟上参数,则会显示指定目录的内容。如图,列出了/system下的内容(这个是安卓系统的目录,普通Linux发行版没有)。
难道ls命令就只有这一个简单的功能吗?当然不是,这些命令都像一直笔一样,即可以拿它来乱涂乱画,也可以写出不朽名篇。输入
- ls / -R
复制代码
会发现屏幕上出现了大量的信息,如图
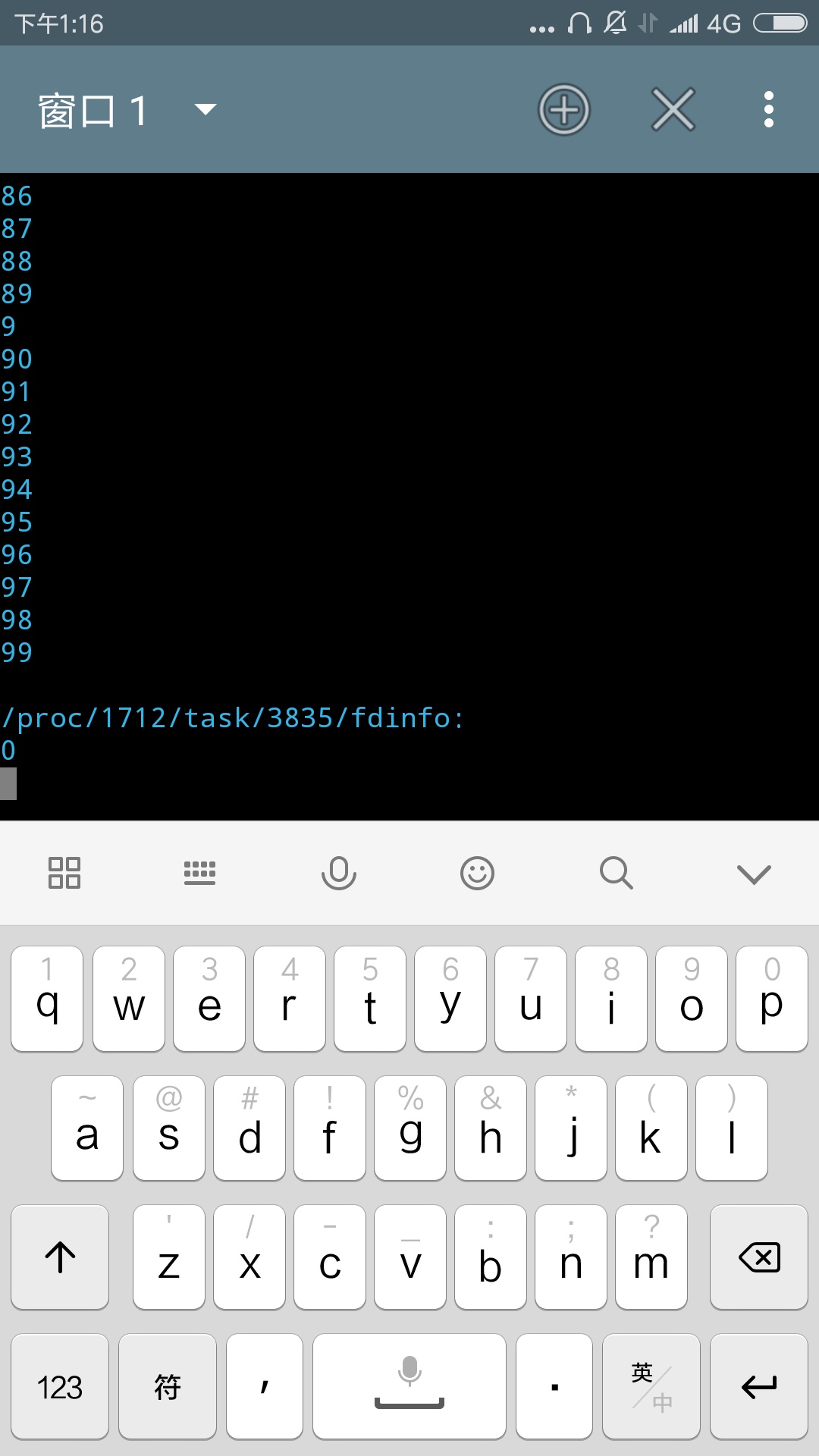
并且,不知道你观察到没有,这次输入的命令后面跟了一个小尾巴“-R”,前面的好理解,“ls /”会列出根目录下的内容,后面的是什么意思?这个“-R”叫做“选项”(其实怎么叫无所谓),选项的作用是指示命令执行的一些具体细节,参数类似于告诉命令做什么,选项类似于告诉命令具体有哪些执行上的要求,比如一个命令“给我打一碗饭,快一点”,打饭是命令本身,“我”是命令作用的主体,而快一点就是告诉命令执行者怎样去打饭,究竟是快一点还是慢一点。“-R”本身的含义是,递归式输出目录下的内容,假如没有这个选项,它只会输出当前目录下的文件盒目录,而下一级目录中的内容就不再输出了。而递归式输出,表示将指定目录下的所有内容,包括子目录,子目录中的子目录……
在这个例子中,参数和选项都是可选的,如果没有参数或者选项,命令有自己默认的执行方式,像
- ls -R
复制代码
- ls /
复制代码
都是合法的而且有意义的。但其他命令就不一定了,具体要看那个命令的说明。一个命令可能不止一个选项,“ls”命令还有的选项,比如“-d ”,“-i”等,它们的含义,可以自行查找资料。再比如命令“rmdir”,它用来删除空目录。
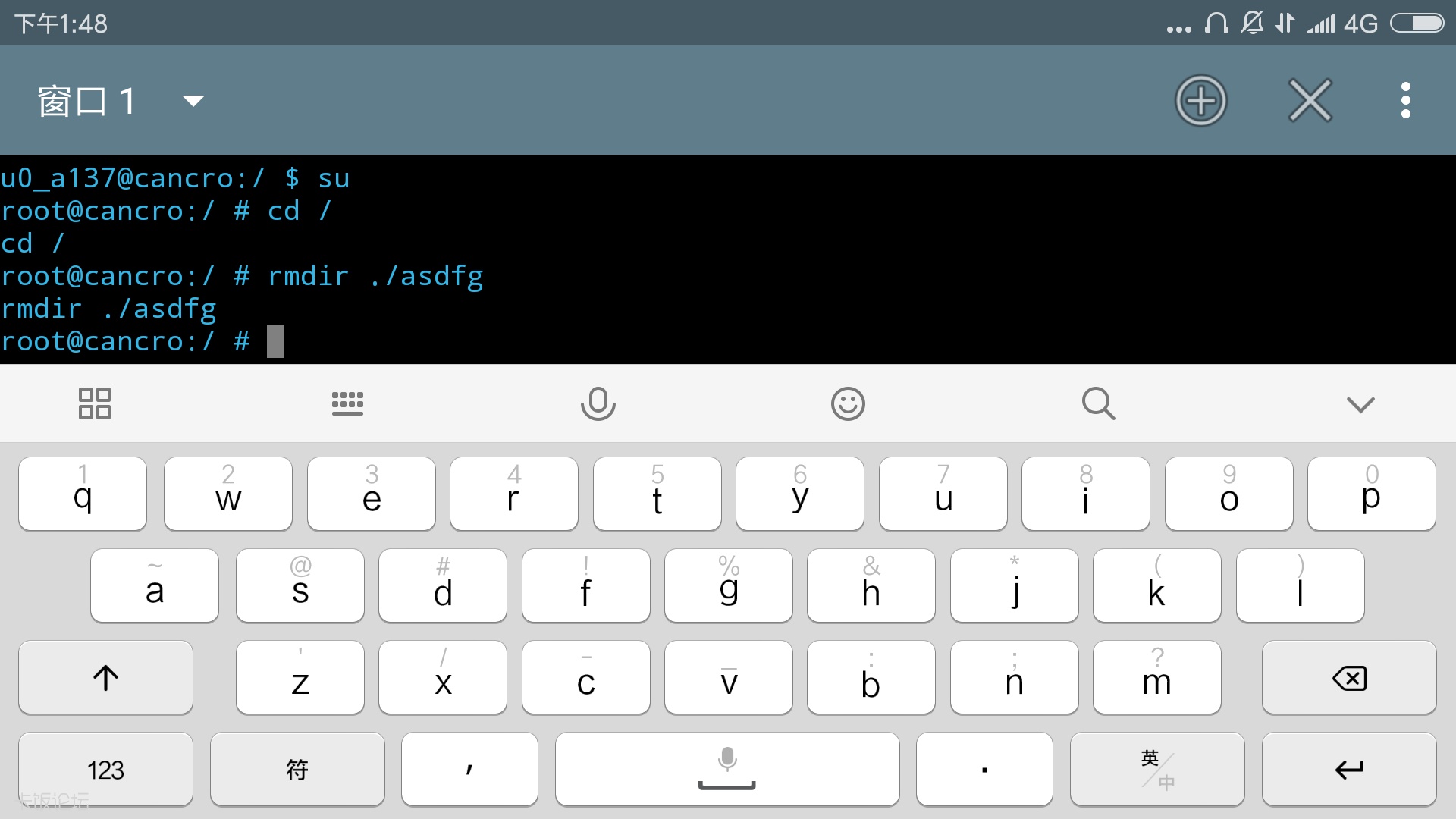
假设“./asdfg”是一个空目录,并且要删除,就可以这样写
- rmdir ./asdfg
复制代码
如图,目录删除成功。
通过查阅资料,得知它有两个选项是“-v”和“–verboes”,意思是显示命令的详细执行过程,不要担心这个“–”,这个也是选项,使用“-v”和“–verboes”都是一样的效果,只不过一个是一个字母的缩写,另一个是英文单词,要用“–”放在这个“长选项”面前。选项也可以取值,比如命令“mysql –host=localhost”(在你的发行版上不一定能够执行),表示选项的值是localhost,它的等价表达是“mysql -h localhost”,也可以是“mysql -h=localhost”,“mysql –host localhost”都可以,但在使用长选项的时候,最好使用“长选项=xxx”或者“短选项 xxx”这种风格。实际上,短选项是Unix的风格,长选项是GNU的风格。注意不一定每一个长选项有与之对应的短选项,一个命令也可以有很多选项同时使用。如果你要使用短选项,可以将命令““rm -r -f /*”写为“rm -rf /*”(不要去随便使用它,尤其是以root账户登录时,因为它会递归式的删除根目录下的所有文件),但是使用长选项,或者短选项需要你去填写一个值,就不能这么简写了。另外,选项大小写不能混用。一个命令可以不只有一个参数,下面这个命令展示了这一点。
可以使用“mv”命令重命名一个文件
- mv /home/f1.cpp f2.cpp
复制代码
第一个参数是/home/f1.cpp,第二个是f2.cpp,表示把第一个参数的文件名字改成第二个参数的内容(当然这个命令的用法有很多,这里只是示例)。具体一个命令有多少参数或者选项,取决于程序的编写者。
常用的命令有很多,以上并没有介绍多少命令,但已经把命令使用的基本方法展示了,对于一些用法不太复杂,不需要太多其他知识的命令,读者可以自行搜索Linux的命令,但像“g++ a.cpp”这种命令就没必要去研究了,假如你不懂什么是C++,再次强调,命令行只是一种使用系统的方式,真正熟练使用,需要对相关机制有所了解才行。
上面所讲的这些命令,好像都将信息输出到了屏幕上,似乎从键盘中读取数据,向屏幕中输出数据,是天经地义的事情。不过,同样也可以将一个命令的输出输出到一个文件中去。
下图中这个命令是介绍过的,但后面跟了一个“>fileinfo.txt”。以下所有的重定向输出都是重定向的“标准输出”,这个概念在下一篇有所涉及。
- ls / -R >fileinfo.txt
复制代码
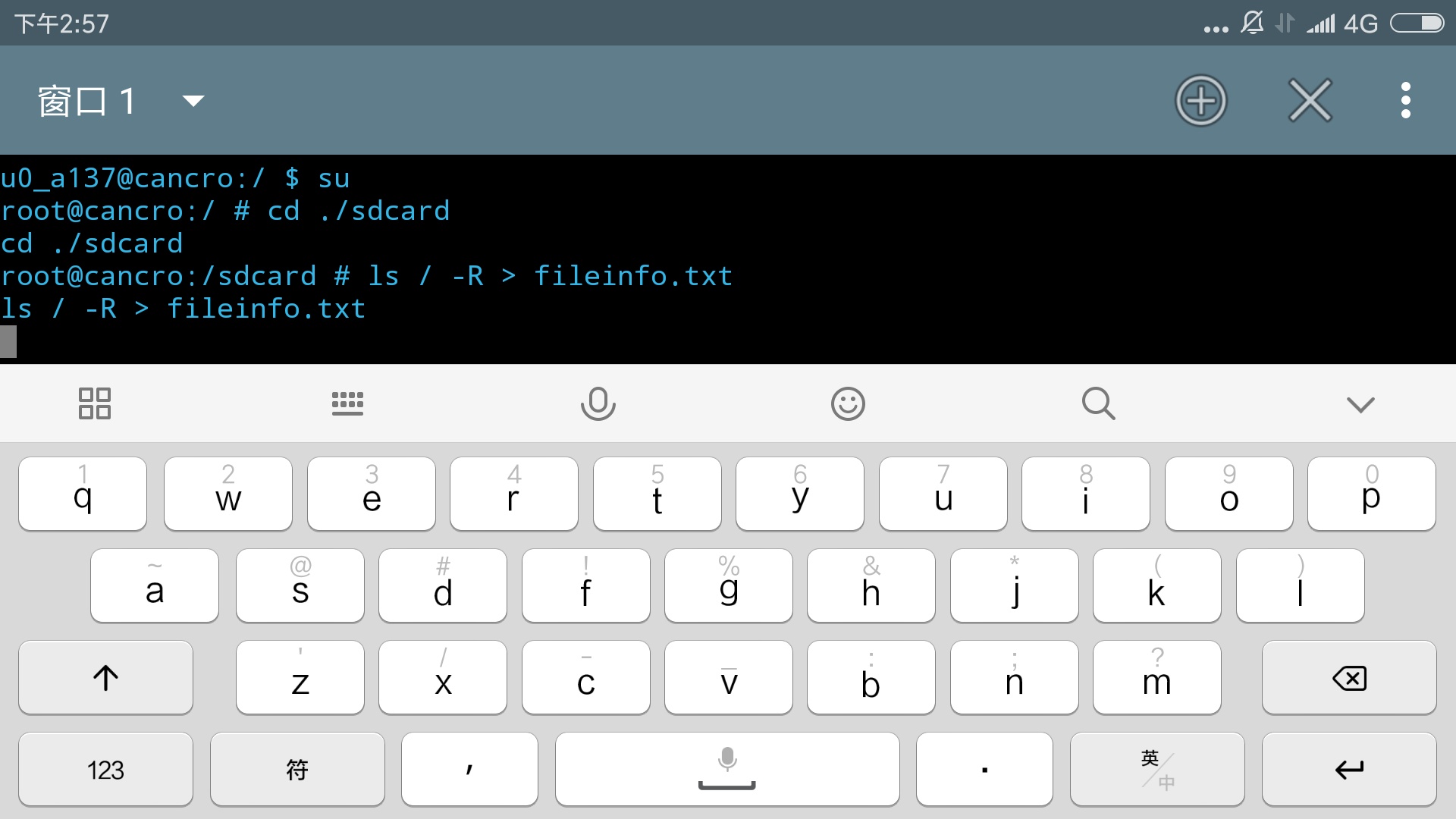
默认情况是将相关信息输出到屏幕,但是这里将其重定向到了一个文件fileinfo.txt中。shell遇到”>”操作符,会判断右边文件是否存在,如果存在就会将原文件的内容清空再写入,不存在的话直接创建。 符号“>>”表示追加输出,如果文件不存在则创建并写入数据,否则会在文件末尾追加要输出的内容,不会清空原文件的内容。上面的命令的执行结果如图11,出现输出信息。
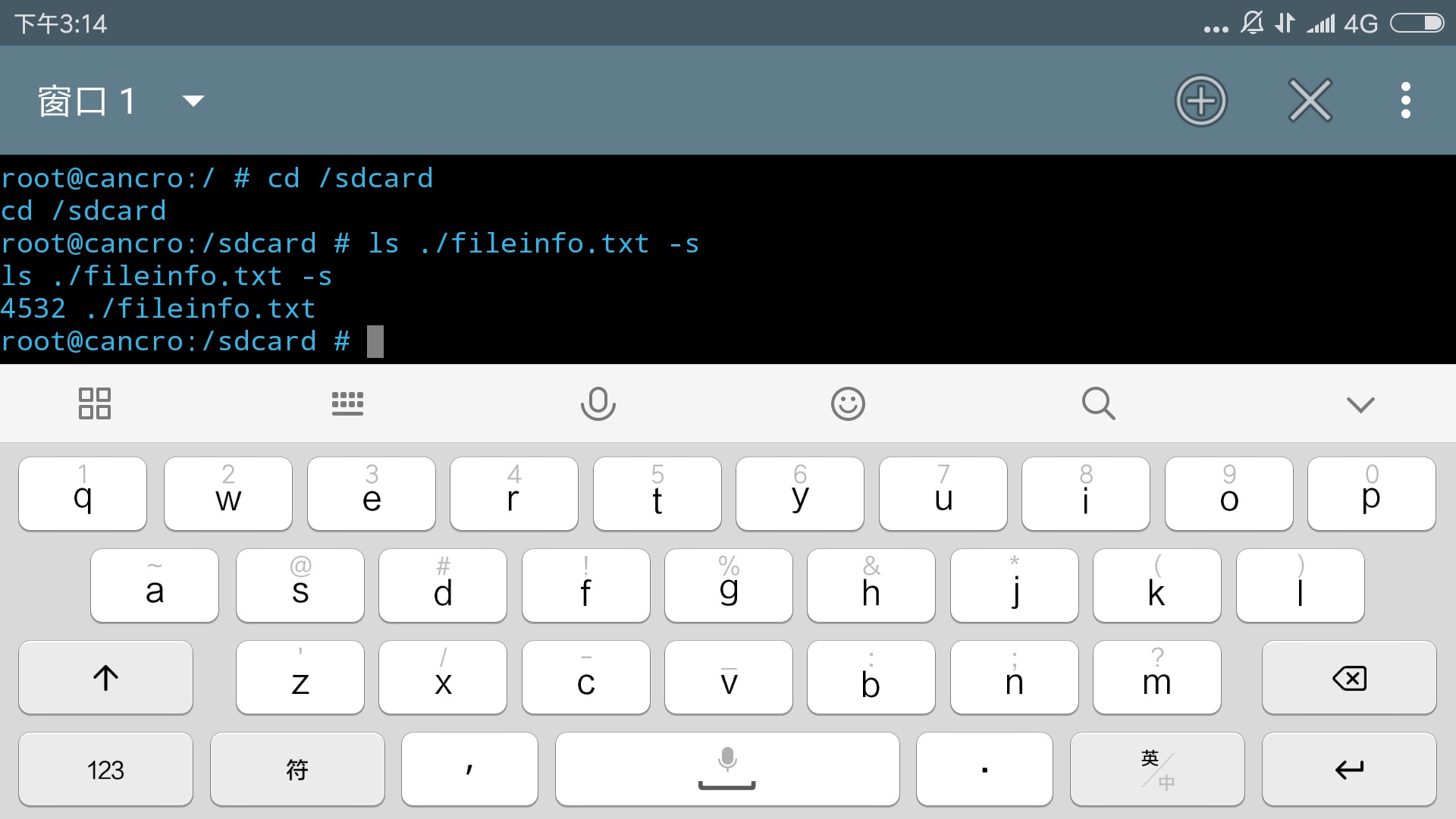
然后使用cat命令将其输出在屏幕上(建议自行搜索这个命令的用法)。
- cat fileinfo.txt
复制代码
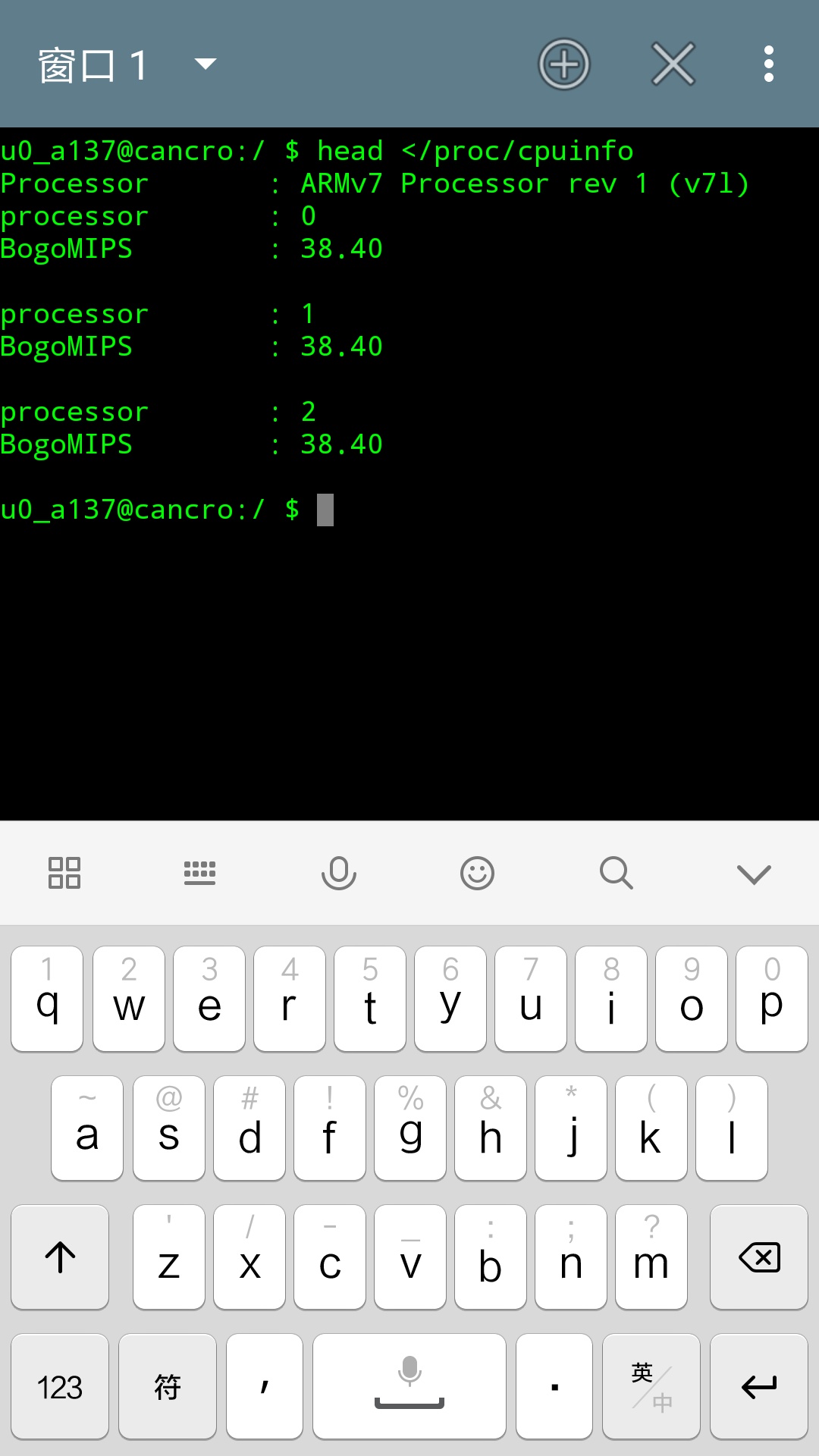
使用重定向输入比较少,因为很多命令可以把文件名当做参数。重定向输入使用“<”符号。如图13。
- head < /proc/cpuinfo
复制代码
文件链接有两种,一种是硬链接(Hard Link),另一种为符号链接(Symbolic Link,也叫做软链接)。
存储设备或设备的分区被格式化为文件系统后,应该有两部份,一部份是inode(information node,索引节,信息节点),另一部份是Block(块),Block是用来存储数据用的。incode用来存储数据的信息,包括文件大小、属主、归属的用户组、读写权限等。inode为每个文件进行信息索引,所以就有了inode的数值。操作系统通过inode值最快的找到相对应的文件。
硬链接指通过索引节点来进行的连接。在Linux的文件系统中,保存在磁盘分区中文件有单独的编号,称为索引节点号(Inode Index)。在Linux中,多个文件名指向同一索引节点是存在的。一般这种连接就是硬链接。硬链接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬链接到重要文件,以防止“误删”的功能。其原因如上所述,因为对应该目录的索引节点有一个以上的链接。删除一个链接并不影响索引节点本身和其它链接,不过,当最后一个连接被删除后,文件的数据块及目录的链接会被释放,此时文件会被删除(有点像C++中的shared_ptr)。
(翼·风 注:可以认为inode是书籍的目录,并包含了一些概要描述信息、连接数等;而Block便是目录指向的具体内容。硬链接相当于给相同的内容的目录下增加了一个指向,对目录指向的修改删除不会影响到具体内容;但若一块具体内容无法被任何目录索引找到,这个内容就相当于不存在,而且白白占据空间,所以当最后的指向目录被删掉后也要删掉对应的内容来释放空间。注意,无论indoe还是Block都不是具体的文件。可参考如:http://blog.csdn.net/u013595419/article/details/51094360)
软链接有点类似于Windows的快捷方式。它是特殊文件的一种(而且不是一个独立的文件,这和Windows不一样 —— 翼·风 注)。在符号链接中,文件实际上是一个文本文件,其中包含的有另一文件的位置。删除了源文件后,链接文件不能独立存在,虽然仍保留文件名,但这个地址是没有意义的。
关于创建硬链接和符号链接的方法,请查阅关于“ln”命令的资料。
P.S. 本文提供的命令参考链接为:http://man.linuxde.net/
本文内容到此结束,读者可以尝试自己使用一些简单的命令,并利用上一篇文章中的获取帮助的方法查找更多命令的用法。当然,这只是个开始。
目录
Ⅰ 前言
Ⅱ 再探I/O重定向
Ⅲ 管道
Ⅳ 键盘操作技巧
V 别名
Ⅰ 前言
折腾≠学习
Linux的发行版有很多,各种各样或精美或简洁的桌面环境吸引着你去安装,各种酷酷的软件看上去不错。于是有些人就认为,折腾=学习。
“吾常终日而思矣,不如须臾之所学也”,即使你作为非专业人员,你也有必要了解下基本的概念,不需要你去了解VFS机制的实现细节,不需要你清楚Linux的进程调度算法,但你至少要知道进程是什么,怎样不通过某些发行版的软件中心安装软件,怎样运行shell脚本等。就像你到了北京去,总得知道有“北京烤鸭”这种东西吧。
楼主并不反对“实践”,但是实践要和理论相结合,虽然有些理论来自于实践,但不代表你就能总得到正确正确的结论,也不能保证你不会走偏。见过这样一批“忠实”的Linux用户:他们不知道deb包和rpm有什么区别,却因自己心仪的几个Linux发行版使用两种包管理方式而不知如何选择,或者就说xx包管理方式比xx包管理方式更先进”;不会不通过GUI界面的软件中心(或类似看起来很友好的软件安装软件),却对怎样配置Wine QQ了如指掌……甚至对Linux仅仅停留在“这是一个开源免费的软件”认识的时候,听别人说“使用Arch Linux才是高手,使用Arch Linux能快速精通Linux”,就照猫画虎的按照教程配置Arch Linux,最后顺便捎带一个Wine QQ之类的软件。
这是“折腾”,并且“折腾无错”,但折腾之后不一定学到了什么,就像你在Windows上折腾了各种花花绿绿的杀毒软件一样,你不一定懂得诸如“注入”之类的词语是什么意思。
所以,要学习,要有正确的方法,当然,为了好玩折腾下没什么问题,但不要陷入这个正反馈的怪圈就行了。
它们不是无意义的符号
有些命令一看就能猜出大概意思,比如“clear”,它是一个英文单词,但是像”cd”,”pwd”这些呢?
为了拼写简便(或者是其他的什么原因),它们经常是一个词组的缩写,比如”cd”指”change directory”,”du”代表”disk usage”。了解这些,可以更快速记住命令。
举例:
ls命令是List的缩写,
cd命令是Change Directory的缩写,
chown命令是 Change Owner 的缩写,
su命令是Swith user的缩写;
cat是 Concatenate的缩写;
df是Disk Free的缩写;
du是Disk Usage的缩写;
ps是Process Status的缩写;
chmod是Change Mod的缩写;
ldd是List Dynamic Dependencies的缩写。
Ⅱ 再探I/O重定向
Unix文化中“一切都是文件”前面已经有所“领略”了,甚至你从键盘上输入命令,从终端输出内容,都与它紧密相关。
每个Linux用户进程创建后,系统自动给它三个特殊文件,为“stdin”,“stdout”,“stderr”(标准输入,标准输出,标准错误输出)。比如命令“pwd”(也把它看做程序),文件“stdin”就表示它的输入,文件“stdout”表示正常的输出,“stderr”表示它输出的错误信息。在之前介绍我们已经知道Linux甚至把鼠标也当做设备文件来使用,这里类似的,这三个文件就是表示这三种信息,这三种信息就是这三个文件。默认情况,标准输入指向键盘,标准输出和标准错误输出指向屏幕。标准输入,标准输出,标准错误输出,指的是这三种信息,而不是有些人认为的“标准输入就是键盘,标准输出就是屏幕,标准错误输出也是屏幕”。上一篇文章我们将标准输出重定向,使其不再连接到屏幕,所以下文的重定向,就可以理解为改换了这三个文件的连接而已。
更近一步想一下,因为“文件是一系列有序列的字节”,这是毫无疑问的。一个程序要运行,可能需要有输入、输出,如果有错,还要能表现出自身的错误。不管是标准输入,标准输出,还是标准错误输出,都是由一个文件代表,也是一串有序列的字节,所以,这样我们也可以把标准输入称为“标准输入流”,以此类推,“标准输出流”,“标准错误输出流”,这是一种形象的说法(把数据比做流水),是另一个层面来看待数据的名称,和“标准输入”,“标准输出”,“标准错误输出”是一个意思。所以“把标准输入流重定向到标准输入”(明显是把标准输出当做“屏幕”这个设备了)这种话是错误的。
*/dev/stdin -> /proc/self/fd/0 #表示标准输入,即键盘输入
/dev/stdout -> /proc/self/fd/1 #表示标准输出,即显示屏,屏幕
/dev/stderr -> /proc/self/fd/2 #表示标准错误输出
如下两张图,第一张毫无疑问命令的用法是正确的,产生的标准输出被重定向到一个文件中,而第二张图就中,因为“pwd”命令没有“-s”这个选项,所以它不会给你正确的信息,它产生了标准错误输出,根据第三篇所写,“>>”和“>”符号仅仅是对标准输出进行重定向,而标准错误输出依然出现在了屏幕上。
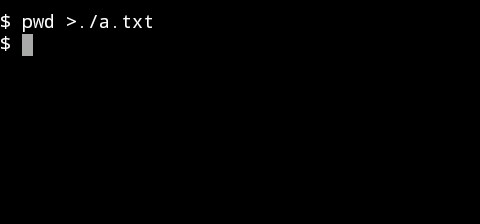
图1:将pwd的标准输出重定向到一个存储在磁盘上的文件中

图2:未重定向标准错误输出
没有专用的重定向标准错误的操作符,如果需要重定向标准错误输出,需要知道其文件描述符。在shell内部,标准输入为0,标准输出为1,标准错误输为 2,观察下面的命令:
pwd >s.txt
pwd 1>s.txt
pwd -s 2>s.txt #重定向标准错误到s.txt
在“>”或者“>>”前面加上数字,就表示了你要重定向什么,没有数字就默认为1,要重定向错误输出,就要指出描述符。
重定向有什么用呢?就目前所讲内容来说,有以下几个好处:
#当屏幕输出的信息很重要,而且我们需要将他存下来的时候;
#背景执行中的程序,不希望他干扰屏幕正常的输出结果时;
#刻意丢弃掉一些输出
#错误讯息与正确讯息需要分别输出时。
要达成以上第三个目的,可以将流重定向到已经提过的“/dev/null”,下面这行命令,就“隐瞒”了可能的错误信息:
ls -l /bin/usr 2> /dev/null
如果我们希望将一个命令的所有输出到一个文件。我们必须同时重定向标准输出和标准错误输出。参考下面的命令:
ls -l /bin >output.txt 2>&1
它表示首先重定向标准输出到文件,然后重定向标准错误输出到标准输出,这样就把两种输出重定向到了一个文件,重定向顺序不能反。就好比三条河流,A,B,C要把A和B的水都输送到C河中,所以就先把A河的水连接到B河,再把B河的水通向C河,这样也就等效于把A,B两条河的水都送到C河。
也有另一种简单的写法(不用太纠结语法,记住即可):
ls -l /bin &>output.txt
Ⅲ 管道
管道是Linux中的一种基本的IPC(进程通信)方式,用于进程间信息传递。数据从管道的写端流入管道,从读端流出,内核使用环形队列机制,借助内核缓冲区实现通信。
不过这里可不会多介绍这些知识,它们牵扯到的其他知识太多了。而这里命令之间传递数据也用了这个机制。
基本语法是如此:
command 1| command 2 |command 3 | …|command n
它的含义是,将command 1的标准输出传递给command 2作为command 2的标准输入,以此类推直到command n,注意标准错误是不能直接这样传递的。
可能你要问了,不是“标准输入”“标准输入”是文件吗?这说明你还没清楚上一小节的内容,标准输出的内容就是抽象为一个特殊文件,这个文件就是标准输出(即一些输入输出的信息)。
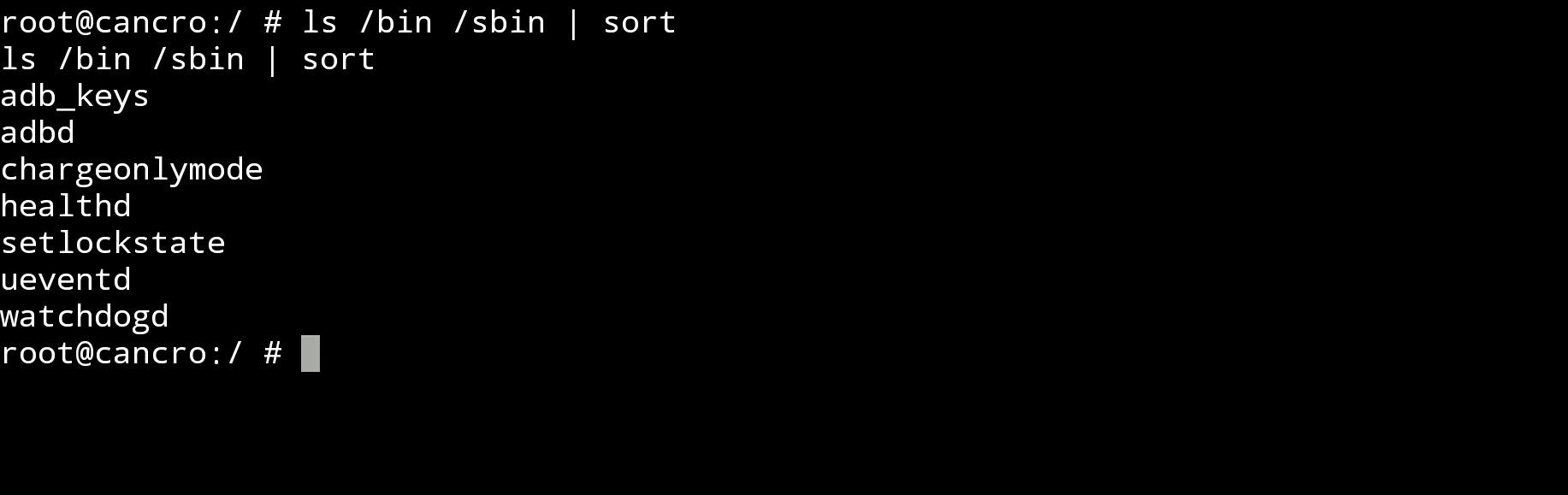
图3:“ls/bin/sbin |sort”的执行
命令 “ls /bin /sbin | sort”的意思是,将这两个目录的内容合起来输出(作为标准输出),而“sort”接受这个标准输出,作为标准输入,然后对其进行排序(sort命令默认以字符排序,其他用法可自行学习,并不难)。
再举一个例子。先介绍一个“厕所命令”,“wc”。wc的用途是统计标准输入中有多少英文单字,行,字符,比如
wc -l /a.cpp
就会输出这个“a.cpp”中有多少个字符,实际上,它是先读取这个文件中的内容,作为标准输入,而不是把这个文件的路径当做标准输入。观察下面的命令:
cat /init.rc | wc -l
首先,cat命令接受一个文件路径为参数,并将其打开,产生标准输出,再将标准输出传递给管道线“|”右边的命令,作为“wc”的标准输入。执行结果如下图:

图4:“cat /init.rc | wc -l”的执行
再举一个特殊的例子,有一个双向重定向的命令,“tee”,它的基本用法是:
tee file
或者
tee -a file
基本作用是,得到标准输入,然后将它输出到文件中和屏幕上。其中,使用选项“-a”为追加模式,不会清空文件内容再写入。举个例子:
ls /bin | sort | tee a.txt
屏幕上输出为(输出内容较多,截取了一部分):

图5:“ls /bin | sort | tee a.txt”的执行
我们再分析一下这个命令的执行过程(已经看懂了的不必再看),首先ls接受/bin这个参数,产生标准输出,也就是/bin目录下的内容,但是这个标准输出通过管道成为了sort的标准输入,随即,sort将它排序,通过管道传输给tee命令,成为tee的标准输入,最后,tee命令将标准输入的内容同时输出在屏幕和文件中。
总结一下,管道线左边的命令必须要能产生标准输出,管道线右边的命令必须要能接受标准输入,这个管道才是有意义的。像命令“less”,“grep”,“cut”等即能接受标准输入,也能产生标准输出,而有些命令,比如“ls”,“pwd”,“type”等就不是了,要么不能接受标准输入,要么不能产生标准输出,甚至都没有。能不能用在管道组合中,判断依据就是上文提到的管道线左右的命令的要求。至于哪些命令能够产生标准输出或者接受标准输入,要靠积累或者查阅资料。
*上述的各种动词,“传递”,“接受”等都是一种形象的容易理解的说法,为了贴合“管道”这个名词。可能你会觉得“读取”,“输出”等动词更加合适。
Ⅳ 键盘操作技巧
有些发行版喜欢标榜自己“很像Windows”,符合“Windows的操作习惯”。可能在窗口程序的应用上做的很像,比如各种快捷键,但在shell中就没法总是符合Windows的一些操作习惯了。
也许你就曾经在终端中使用“Ctrl +V”和“Ctrl+C”操作文本,但发现屏幕上会产生莫名其妙的情况。在使用shell的时候,合理使用键盘操作技巧,有助于提高效率。下面介绍一些常用的快捷键,不难但是比较多,只要多用就会了。现在的很多发行版中的终端使用鼠标操作也不麻烦,如果你真想用鼠标。
(你猜猜我为什么要用“#”这个符号?)
#Ctrl-A 移动光标到行首(光标,就是那个发亮的小长方条,不是鼠标指针)
#Ctrl-E 移动光标到行末(可以思考下A和E是什么意思,方便记忆)
#Ctrl-L 清空屏幕,和输入命令“clear”一样的效果
#Ctrl-D 删除光标所指的字符
#Ctrl-T光标位置的字符和光标前面的字符互换位置。
#Ctrl-K剪切从光标位置到行尾的文本
#Ctrl-U剪切从光标位置到行首的文本
建议亲自体验一下上面的快捷键,搞清楚它们什么意思,具体细节,可以自己体会。常用快捷键不止这些,可以自行搜索。
下面提一个东西叫“自动补全”,看下面这张图就明白了。
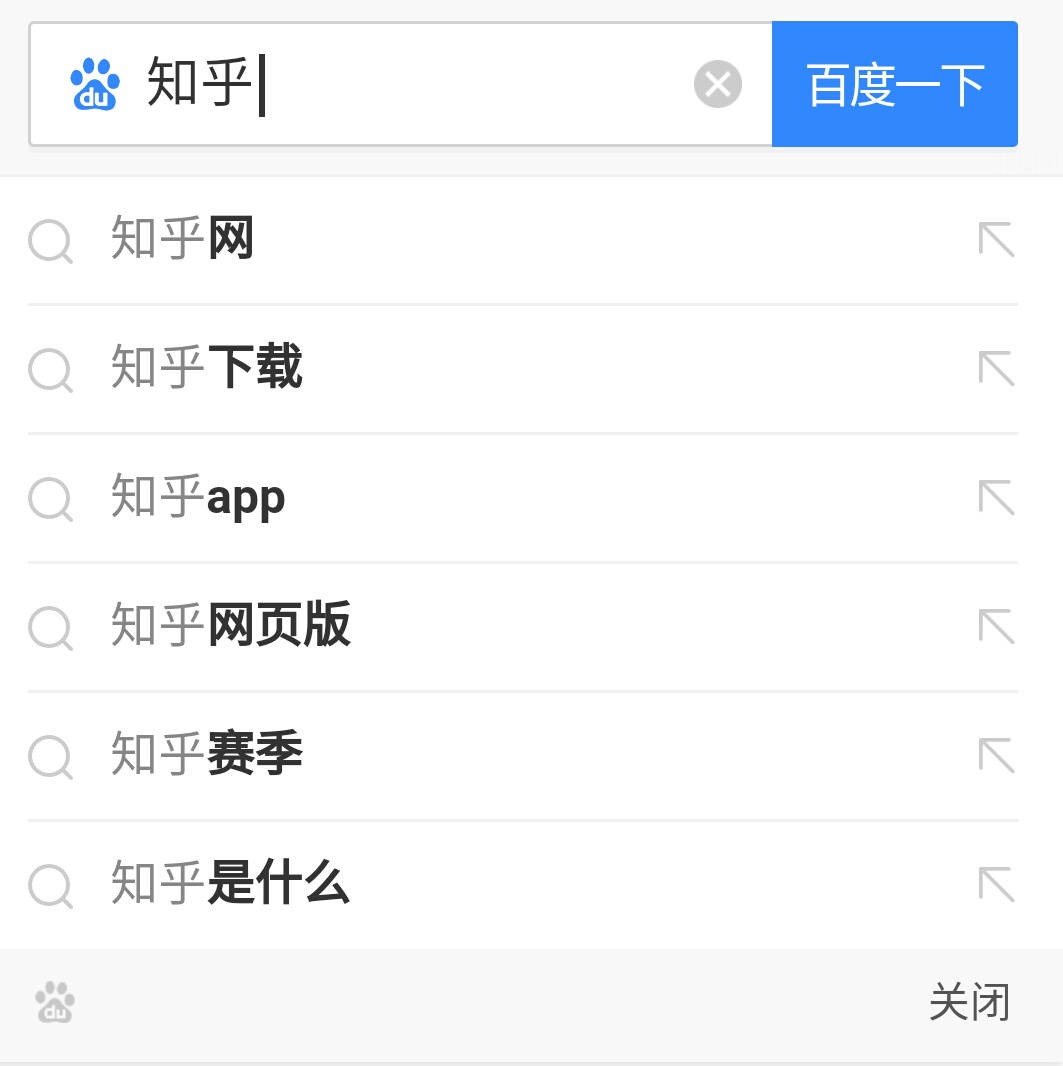
图6:搜索引擎的“自动补全”功能
无非是给你一个“偷懒”的机会,让你少输点东西,免得出错,也可能在你不知道怎么做的时候给一点提示。
比如输入字符“pw”,再按一下Tab键,就会自动补全“pwd”这个命令。输入字符“s”,按两次Tab键,会出现所有以“s”开头的命令。

图7:列出以“s”开头的命令
自动补全能对变量、用户名、命令和主机名等起作用(主机名自动补全只对包含在文件/etc/hosts 中的主机名有效)。具体例子在以后涉及(变量,用户名等概念未讲述)。
这只是最基本的补全功能,你也可以安装一些增强工具包,甚至你的发行版自带的终端功能就很“高级”,但基本作用就是提示和补全。
V别名
在Windows Powershell中,清空屏幕可以用“Clear-Host”,在bash上可以用“clear”,如果我喜欢Windows Powershell的写法呢?
“alias”命令用来设置指令的别名。我们可以使用该命令可以将一些较长的命令进行简化,当然也可以拿来完成上一段所讲的目的。
它的基本用法是:
alias 别名=’原命令 -选项/参数’
比如:
alias Clear-Host=’clear’
alias cls=’clear’
alias Get-LineCount=’wc -l’

图8:设置别名
要删除一个别名,可以使用 unalias 命令,用法请自行搜索(尝试一下输入“man unalias”并观察屏幕上的输出)。
alias命令的作用只局限于该次登录的。若要每次登入都能够使用这些命令别名,则可将相应的alias命令存放到bash的初始化文件/etc/bashrc(对所有用户启动的shell都有效) 。
用任意编辑器打开这个文件,如下图框出的地方就可以设置“永久别名”,语法参考图中示例。暂时不要在不清楚本文件其他用途的时候随意修改。
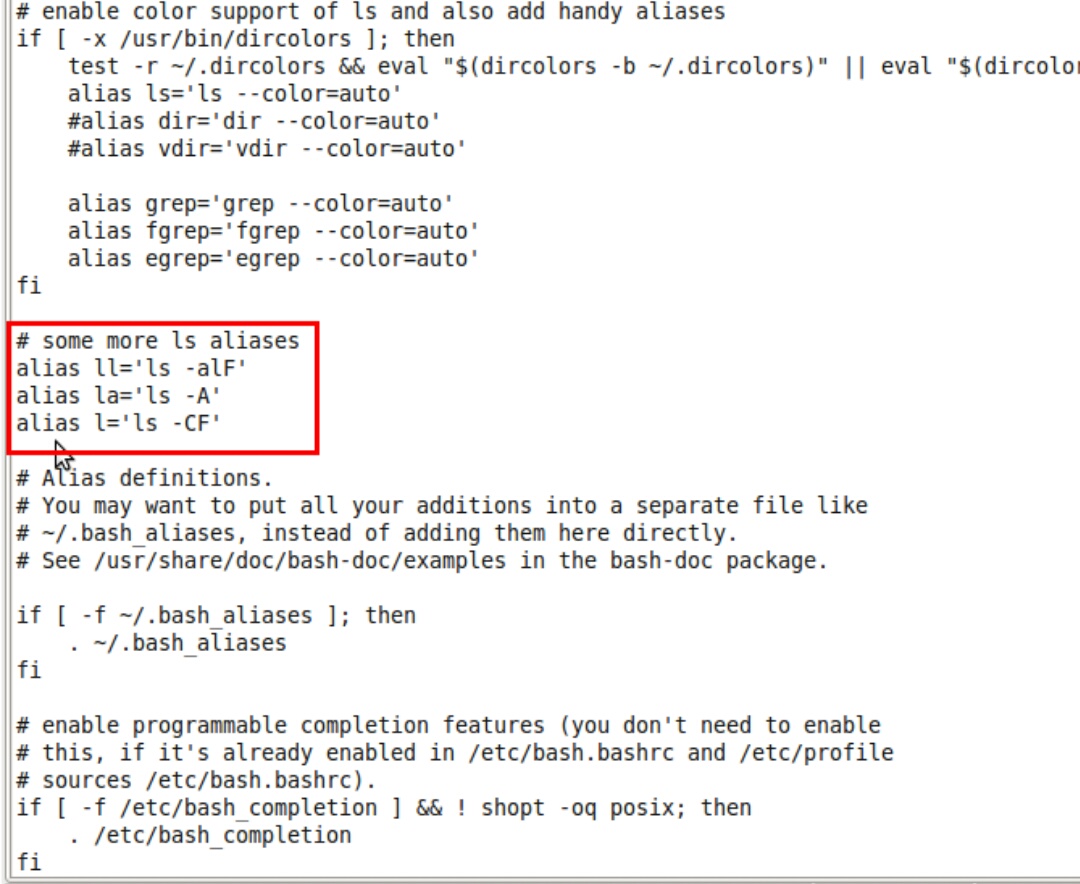
图9:打开配置文件
本篇文章的重点在于理解I/O重定向的用法。对于管道的使用,并没有过多的例子,这会在以后提到。也许目前为止感觉不到这些东西有什么大用,其实在具体应用场景中,才能体会到它们的好处。

目录
Ⅰ 前言
Ⅱ 命令echo和read
Ⅲ shell中变量的设置与输出
Ⅳ 简单认识用户与用户组
V Linux文件基本属性
Ⅰ 前言
xx和xx哪个好?
“Fedora和Ubuntu哪个好?”,“Emacs和Vim哪个好?”,“Bash和Powershell哪个好?”……
判定哪个好的依据是什么?另一方“不好又是为什么”。回答这个问题的人,往往就是因为自己在用一个,而去贬低另一个。口水战和脑残粉是互联网特色,但对于真正想了解某一个知识的人来说,这些纷争毫无用处。可能今天你刚把ArchLinux配置好,明天就有人说FreeBSD比Linux好,过几天,又会见到“Windows最好”的理论。
对于一项广泛使用的东西来说,它必定有自己的优点,也会有不足,好不好取决于你的需求。你想写爬虫?对,这个时候C语言的确“不好”,想写一个Windows的驱动程序?对不起,这个时候Python是一团糟,除非你能自己写一个编译器,还要无缝贴合WDK。
综上,强烈不建议“墙头草”这样去纠结什么什么好不好,而只在于这些怎么用有价值。当然,比较是应该的也是必须的,但远不是“FreeBSD比Linux好”这种没有根据的口水结论一样简单。
Ⅱ 命令echo和read
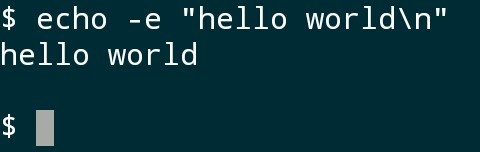
如图,是使用echo命令的三个例子,它用来向屏幕输出字符信息,参数就是字符串(有序列的字符就是字符串),它可以被重定向到文件。

第一个没有引号,第二个是单引号,第三个是双引号(只能是英文中的引号),引号作为字符串的边界,不是字符串本身的内容。
如果给它使用-e选项时,若字符串中出现以下字符,则特别加以处理,而不会原样输出:(注意都是反斜杠)
- \a 发出警告声;
- \b 删除前一个字符;
- \c 最后不加上换行符号;
- \f 换行但光标仍旧停留在原来的位置;
- \n 换行且光标移至行首;
- \r 光标移至行首,但不换行;
- \t 插入tab;
- \v 与\f相同;
- \\ 插入\字符;
- \nnn 插入nnn(八进制)所代表的ASCII字符;
复制代码
因为有些字符不太方便直接写出来,需要用其他字符的组合表示出来,比如换行符,退格符,制表符等。这些字符也叫“转义字符”。如果不使用选项“-e”,字符串会原样输出。

如果我们使用-e选项,会是以下的输出。如果字符串不加任何引号,则不要使用转义字符,符号“\”不表示转义,如果想知道它的意思,请做一个实验,输入“cd \”回车,此时没有执行命令,还让你输入,再输入“/home\”,还是让你继续输入,直到没有“\”跟在输入后面,这时候命令就被识别成了“/home/xxx”。综上可得,这是一个将一个很长的命令可以分成多行书写的方法。
默认输出产生在屏幕上,也可以重定向标准输出,输入命令“echo Hello |tee -a a.out”(结合上一篇的管道去理解)。

学会屏幕上输出,也要懂得从标准输入读取数据,就需要用到read命令。
输入命令“read name”,这个时候,屏幕会“停下”,等待你输入内容,然后将所接收的数据存储在变量“name”中(稍后介绍变量)。
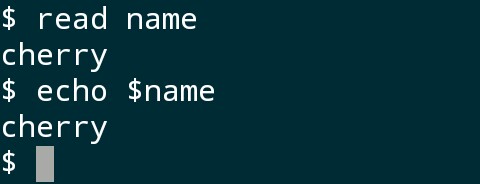
图中变量name的值为输入的“cherry”,再用echo输出,符号$name表示引用这个变量的值,否则“echo name”会直接把字符串“name”输出。
选项“-p”可以在请求输入的同时在屏幕上输出提示信息,比如命令“read -p “Enter your name: ” ” ,虽然你没有指定一个变量让read把读到的内容写入,但它默认会写入到变量“REPLY”中,可以使用“echo $REPLY”输出。
有些输入需要在特定的时间完成,因此可以限制输入时间,否则“过期不候”,比如“read name -t 30”表示等待30秒,如果没有得到内容,变量“name”就是空的。
这两个命令的用法还不止这些,这里只介绍了最基本的。
Ⅲ shell中变量的设置与输出
变量是什么?
可能你听过“环境变量”这个概念,或者在各种编程需要中接触过。变量,在逻辑上讲,就是一项数据的符号表示,这项数据可以是字符串,数字,甚至是其他更复杂的数据类型。我们都做过小学应用题,比如“一筐苹果,红的比黄的多2个,一共有10个苹果,有几个黄苹果?”,解答往往是“设有x个黄苹果……”此时,这个“x”就是变量,它代表了黄苹果的数量。
(翼·风 注:你也可以把变量想象成一个空空的水桶,用来填东西,但是具体填什么是不确定的&可改变的,可以先存半桶水,再存一桶水,再倒掉,换成一桶牛奶,其中的内容随时可变,只不过调用的时候说:我就要这个桶里东东!)
我们也在shell中定义一个变量,输入“username=cherry”(等号两边不要有空格)此时,username就是一个变量,它代表了值“cherry”,我们可以用echo命令把它输出,如图。

符号$表示引用变量的值,比如echo $username就会输出username实际的内容,也可以使用echo ${username}。
我们把给变量给定一个值的过程叫赋值。上述也可以写成“username=”cherry””或者”username=’cherry'”。
变量名和等号之间不能有空格,这可能与很多编程语言都不一样。同时,变量名的命名须遵循如下规则:
命名只能使用英文字母,数字和下划线,首个字符不能以数字开头。中间不能有空格,可以使用下划线(_)。不能使用标点符号。不能使用bash里的关键字(可用help命令查看保留关键字)。变量区分大小写,name和NAME是不同的。
以下变量名是合法的:
- name
- ___
- _school
- date_EXT
复制代码
以下是不合法的:
- 2hello
- !ss
复制代码
给一个变量赋值后,可以给它一个新值,比如输入”a=ni;a=wo”(中间的分号表示,执行第一条命令后执行下面的一条,不管第一个有没有执行成功,类似的,也可以写出“ls ;pwd;cd /”这样的命令组合),此时a的值是“wo”,在给变量赋新值时,不能在要赋值的变量前面加“$”。变量之间也可以互相赋值。
前面我们用了两种引号,那么它们有什么区别呢?输入以下命令“a=n;echo ‘$a’”和“a=n;echo
“$a””,分别产生不同的输出,如图。
单引号内的变量表达形式$var这种不会被解析,会原样输出,而双引号内的变量会被解析成变量的内容,此外,单引号内不能再有单引号,转义也不行。
默认情况,变量内容会被当做字符信息,不是数字,比如a=1,这表示a为字符1而不是整数1,见下图,不能直接对这样的变量执行算数运算。

要想将一个变量声明为指定类型,其语法为:
- declare(或typeset) [-aixr] 变量名
复制代码
参数:
- -a :声明为数组类型
- -i :声明为整型
- -x :声明为环境变量(功能与 export 相同)
- -r :声明为只读类型,此变量声明后不能更改内容,也不能撤销(与readonly相同,如readonly a=name)
复制代码
如下图,将变量指定为整数,得到了正确结果。

bash不直接支持浮点数(也就是小数),但我们有很多方法处理小数。本文中很少用到数学计算,所以目前不再多介绍怎么处理非字符型变量,在shell脚本中会介绍。
刚才我们使用的变量,都是局部变量,运行shell时,会同时存在三种变量:
1) 局部变量:局部变量在脚本或命令中定义,仅在当前shell实例中有效,其他shell启动的程序不能访问局部变量。
2) 环境变量:所有的程序,包括shell启动的程序,都能访问环境变量,有些程序需要环境变量来保证其正常运行。必要的时候shell脚本也可以定义环境变量。
3) shell变量:shell变量是由shell程序设置的特殊变量。shell变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了shell的正常运行。
常见的环境变量有:
- PATH 决定了shell将到哪些目录中寻找命令或程序
- HOME 当前用户主目录
- HISTSIZE 历史记录数
- LOGNAME 当前用户的登录名
- HOSTNAME 指主机的名称
- SHELL 当前用户Shell类型
- LANGUGE 语言相关的环境变量,多语言可以修改此环境变量
- MAIL 当前用户的邮件存放目录
复制代码
环境变量在使用上,和局部变量都一样,如“echo $HOME”如图:
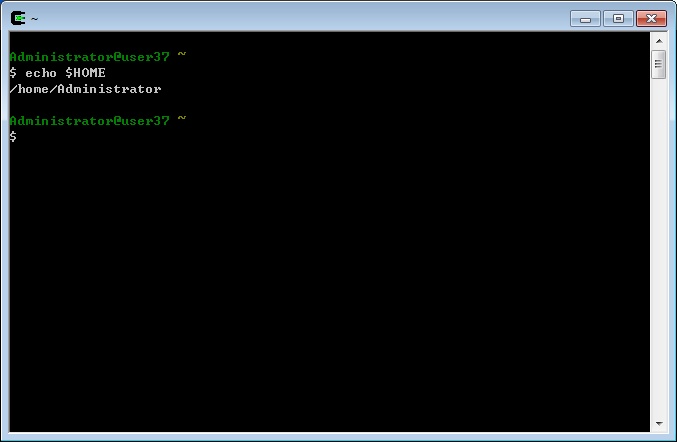
还有一些有趣的环境变量,如RANDOM,每次访问它,都会给你一个随机数,如图:

环境变量可以被当前进程和子进程访问(运行中的程序叫进程,由当前进程启动的进程叫子进程)。
如图,定义了一个局部变量a,再打开另一个bash,它就是当前进程的子进程,只是显示在同一个终端,由图可得,它没办法访问变量a,我们用命令exit退出,再使用export命令将a转变为环境变量,这样,子进程就可以访问变量a了。
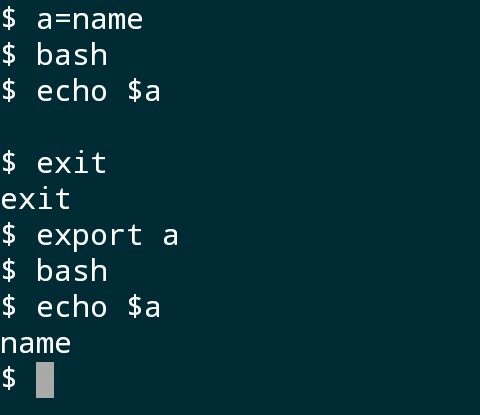
但是,这样的环境变量是暂时的,重新启动shell后就没了,而系统默认的环境变量是从一个配置文件中执行的,已经初始化好,所以不用再定义。
设置环境变量相关方法(无需求的话不要随便改),可能有些发行版有所不同:
1.修改/etc/profile文件,影响所有用户。/etc/profile在系统启动后第一个用户登录时运行。举例:在/etc/profile文件中添加
- export PATH=/home/cherry/lib:$PATH
复制代码
要使修改生效,可以重启系统,或者执行
- source /etc/profile
- echo $PATH
复制代码
2.修改/etc/environment,也将影响全局。/etc/environment文件与/etc/profile文件的区别是:/etc/environment设置的是系统的环境,而/etc/profile设置的是所有用户的环境,即/etc/environment与用户无关,在系统启动时运行。
3.修改~/.bash_profile,最好这么做。将影响当前用户。
4.修改/etc/bashrc(也有可能是/etc/bash.bashrc),影响所有用户使用的bash shell。/etc/bashrc顾名思义是为初始化bash shell而生,在bash shell打开时运行。这里bash shell有不同的类别:登录shell和非登陆shell,登录shell需要输入用户密码,例如ssh登录或者su – 命令提权都会启动login shell模式。non-login shell不会执行任何此类文件;运行脚本文件是非交互shell模式,一般情况下不执行任何bashrc文件(当然可以手动执行)。所以,要不要修改这个文件,取决于你的需求。
5.修改~/.bashrc,影响当前用户使用的bash shell。
6.在终端中执行命令,只影响当前终端。
shell中的一些特殊变量,有些特殊意义,例如变量$代表当前进程的PID,变量?代表上个命令执行的返回值,变量0代表shell脚本文件名,如果终端中输入,返回的是shell名称。没有乱码,变量名字是有些怪。它们的应用,留在脚本中说明
Ⅳ 简单认识用户与用户组
Linux是多任务系统,多用户系统。它意味着多个用户可以在同一时间使用同一台计算机。然而一个个人计算机可能只有一个键盘和一个屏幕,但是它仍然可以被多个用户使用。例如,远程用户通过 ssh(安全 shell)可以登录并操纵这台电脑。 事实上,远程用户也能运行图形界面应用程序,并且图形化的输出结果会出现在远端的显示器上。
任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统。在安装Linux时,你应该创建了一个用户。用户账号可以帮助系统管理员对使用系统的用户进行监测,并控制他们对系统资源的访问;也可以帮助用户组织文件,并为用户提供安全性保护。比如,有两个用户cherry和yifeng,cherry同属于一个用户组Group1,他们之间可以控制哪些文件是私有的,哪些文件对方可以读取,写入,执行等等。用户的划分,让不同的用户尽可能不要相互干扰。
设计用户组的目的类似,任意用户可能从属某个用户组,而且一个用户可以属于很多个用户组,以便拥有这些组的权限。此外用户也能够新加入某些已经存在的用户组,以获取该组所拥有的特权。假设Mary和Bob在完成一个项目,它们属于用户组Group2,因为共同完成项目,所以可以设置某些文件是组内共享,如果有一个用户组Group3经常“参考”他们的成果,可以设置让这个用户组内的所有用户无法访问这些文件,假设老板Tom属于用户组Boss,就可以设置Boss这个用户组的权限。
对于每个用户,都有自己的UID(不同的发行版可能有差异):
- 0 表示管理员(root)
- 1 – 500 表示系统用户
- 501 – 65535 表示普通用户(实际上,目前可以使用的数字远大于65535,是2^32-1)
复制代码
如果一个用户的UID设置为0,那么它就是超级用户,几乎可以干任何事,比如删除其他用户的文件。
总的来说,Linux 通过用户和用户组实现访问控制,包括对文件访问、设备使用的控制。Linux 默认的访问控制机制相对简单直接,不过还有一些更加高级的机制,包括 ACL 和 LDAP authentication。用户,用户组,权限等词语听起来好高深,不要被它们吓到了。不要拿它们和Windows比较,“哪个好”,毕竟你不一定真的理解Windows的权限管理机制。
如果要对用户用户组进行操作,可以使用GUI界面的设置中心,各种Linux发行版可能不一样。也可以使用命令,相关的命令有:useradd,userdel,usermod,passwd,groupadd groupdel,groupmod等等。请自行查阅。
V Linux文件基本属性
输入命令“ls -l”,输出如下:
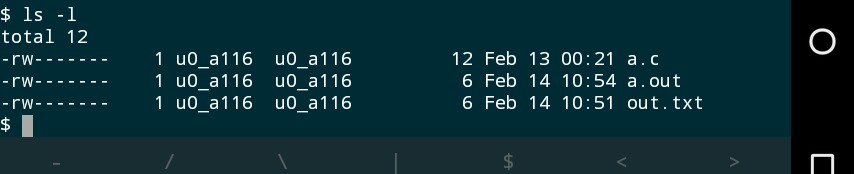
列表的前10个字符描述了文件的权限属性,第一个字符表示文件类型
- – 一个普通文件
- d 一个目录
- l 一个符号链接。对于符号链接文件,剩余的文件属性总是”rwxrwxrwx”,真正的文件属性是指符号链接所指向的文件的属性。
- c 一个字符设备文件。这种文件类型是指按照字节流来处理数据的设备。比如说终端机或者调制解调器
- b 一个块设备文件。这种文件类型是指按照数据块来处理数据的设备,这里不做过多介绍。
复制代码
剩下的九个字符叫做文件模式,代表着文件所有者、文件组所有者和其他人的读、写和执行权限。第2,3,4个字符表示当前文件拥有者的权限,比如“rwx”表示可以读取,写入,执行,假设没有执行权限,应该用“-”占位不能空缺,如“rw-”,后面的第5,6,7个字符表示用户所在组的用户的权限,剩下的表示其他人的权限。如下图

详细的来说,r对于文件来说,意味着允许打开并读取文件内容,对于目录来说允许列出目录中的内容,前提是目录必须设置了可执行属性(x)。
w对于文件来说,允许写入文件内容或截断文件。但是不允许对文件进行重命名或删除,对于目录来说,允许在目录下新建、删除或重命名文件,前提是目录必须设置了可执行属性(x)。
x对于文件来说,允许将文件作为程序来执行,比如clang生成的一个二进制程序文件a.out,需要有x权限,对于目录来说,意味着允许进入目录,例如:cd directory ,如果目录没有x权限,目录的其他权限一切都没有意义。
举个例子,drwxrwx—表示 一个目录,文件所有者以及文件所有者的组成员可以访问该目录,并且可以在该目录下新建、重命名、删除文件。再比如-rw——-表示一个普通文件,对文件所有者来说可读可写。其他人没有任何权限。
可以使用命令chmod改变文件模式,例如有一个文件a.cpp,命令“chmod u=rwx,g=rw,o=r a.cpp”表示把这个文件的文件模式改为“-rwxrw-r–”参数中的u,g,o分别代表所有者,所有者所在用户组,其他人。用等号会覆盖掉原来的值。你也会看到诸如“chmod 764 a.cpp
chmod a+x a.cpp”的表达,第一个764是什么意思?r 读取权限,数字代号为“4”;w 写入权限,数字代号为“2”;x 执行或切换权限,数字代号为“1”;- 不具任何权限,数字代号为“0”;每三个为一组,如果文件所有者的权限是“rwx”,那么第一个数字就是4+2+1=7,如果所有者所在用户组的权限是“r–”,那么第一个数字就是1,以此类推。第二个命令中的a表示“all”,加号代表添加权限,不会像等号一样完全覆盖,例如“chmod u+x a.cpp”表示给文件所有者添加可执行权限,同样的还有减号,用来去除权限。这几种表达都可以使用。
还有两个命令“chown”,“chgrp”。第一个表示更改文件所有者,第二个表示更改组。只有文件所有者和超级用户才可以便用该命令。
有关的命令建议自己查询用法,这里不再赘述。
本篇文章中,在屏幕上输入输出是基本的能力,而如果要成为一名合格的Linux用户,至少要清楚用户,用户组,文件属性这些概念。它们都属于最基础的知识。